Joint Models for Longitudinal and Time-to-Event Data
jm.RdFits multivariate joint models for longitudinal and time-to-event data.
Usage
jm(Surv_object, Mixed_objects, time_var, recurrent = FALSE,
functional_forms = NULL, which_independent = NULL,
base_hazard = NULL, data_Surv = NULL, id_var = NULL,
priors = NULL, control = NULL, ...)
value(x, IE_time = NULL)
coefs(x, zero_ind = NULL, IE_time = NULL)
slope(x, eps = 0.001, direction = "both", IE_time = NULL)
velocity(x, eps = 0.001, direction = "both", IE_time = NULL)
acceleration(x, IE_time = NULL)
area(x, time_window = NULL, IE_time = NULL)
Delta(x, time_window = NULL, standardise = TRUE, IE_time = NULL)
vexpit(x)
Dexpit(x)
vexp(x)
Dexp(x)
vabs(x)
vlog(x)
vlog2(x)
vlog10(x)
vsqrt(x)
poly2(x)
poly3(x)
poly4(x)
tv(x, knots = NULL, ord = 2L)Arguments
- Surv_object
an object:
of class 'coxph' fitted by function
coxph()from package survival, orof class 'survreg' fitted by function
survreg()from package survival.
- Mixed_objects
a
listof objects or a single object. Objects may be:of class 'lme' fitted by function
lme()from package nlme, orof class 'MixMod' fitted by function
mixed_model()from package GLMMadaptive.
- time_var
a
characterstring indicating the time variable in the mixed-effects model(s).- recurrent
a
characterstring indicating "calendar" or "gap" timescale to fit a recurrent event model.- functional_forms
a
listof formulas. Each formula corresponds to one longitudinal outcome and specifies the association structure between that outcome and the survival submodel as well as any interaction terms between the components of the longitudinal outcome and the survival submodel. See Examples.- which_independent
a numeric indicator matrix denoting which outcomes are independent. It can also be the character string
"all"in which case all longitudinal outcomes are assumed independent. Only relevant in joint models with multiple longitudinal outcomes.- base_hazard
a
charactervector indicating the type of hazard function.- data_Surv
the
data.frameused to fit the Cox/AFT survival submodel.- id_var
a
characterstring indicating the id variable in the survival submodel.- priors
a named
listof user-specified prior parameters:mean_betas_HCthe prior mean vector of the normal prior for the regression coefficients of the covariates of the longitudinal model(s), which were hierarchically centered.
Tau_betas_HCthe prior precision matrix of the normal prior for the regression coefficients of the longitudinal model(s), which were hierarchically centered.
mean_betas_nHCa
listof the prior mean vector(s) of the normal prior(s) for the regression coefficients of the covariates of the longitudinal model(s), which were not hierarchically centered.Tau_betas_nHCa
listof the prior precision matrix(ces) of the normal prior(s) for the regression coefficients of the longitudinal model(s), which were not Hierarchically Centered.mean_bs_gammasthe prior mean vector of the normal prior for the B-splines coefficients used to approximate the baseline hazard.
Tau_bs_gammasthe prior precision matrix of the normal prior for the B-splines coefficients used to approximate the baseline hazard.
A_tau_bs_gammasthe prior shape parameter of the gamma prior for the precision parameter of the penalty term for the B-splines coefficients for the baseline hazard.
B_tau_bs_gammasthe prior rate parameter of the gamma prior for the precision parameter of the penalty term for the B-splines coefficients for the baseline hazard.
rank_Tau_bs_gammasthe prior rank parameter for the precision matrix of the normal prior for the B-splines coefficients used to approximate the baseline hazard.
mean_gammasthe prior mean vector of the normal prior for the regression coefficients of baseline covariates.
Tau_gammasthe prior precision matrix of the normal prior for the regression coefficients of baseline covariates.
penalty_gammasa character string with value 'none', 'ridge', or 'horseshoe' indicating whether the coefficients of the baseline covariates included in the survival submodel should not be shrunk, shrank using ridge prior, or shrank using horseshoe prior, respectively.
A_lambda_gammasthe prior shape parameter of the gamma prior for the precision parameter of the local penalty term for the baseline regression coefficients. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.B_lambda_gammasthe prior rate parameter of the gamma prior for the precision parameter of the local penalty term for the baseline regression coefficients. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.A_tau_gammasthe prior shape parameter of the gamma prior for the precision parameter of the global penalty term for the baseline regression coefficients. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.B_tau_gammasthe prior rate parameter of the gamma prior for the precision parameter of the global penalty term for the baseline regression coefficients. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.A_nu_gammasthe prior shape parameter of the gamma prior for the variance hyperparameter for the precision parameter of the local penalty term for the baseline regression coefficients. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.B_nu_gammasthe prior rate parameter of the gamma prior for the variance hyperparameter for the precision parameter of the local penalty term for the baseline regression coefficients. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.A_xi_gammasthe prior shape parameter of the gamma prior for the variance hyperparameter for the precision parameter of the global penalty term for the baseline regression coefficients. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.B_xi_gammasthe prior rate parameter of the gamma prior for the variance hyperparameter for the precision parameter of the global penalty term for the baseline regression coefficients. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.mean_alphasthe prior mean vector of the normal prior for the association parameter(s).
Tau_alphasthe prior mean vector of the normal prior for the association parameter(s).
penalty_alphasa character string with value 'none', 'ridge', 'horseshoe' indicating whether the coefficients association parameters should not be shrunk, shrank using ridge prior, or shrank using horseshoe prior, respectively.
A_lambda_alphasthe prior shape parameter of the gamma prior for the precision parameter of the local penalty term for the association parameters. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.B_lambda_alphasthe prior rate parameter of the gamma prior for the precision parameter of the local penalty term for the association parameters. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.A_tau_alphasthe prior shape parameter of the gamma prior for the precision parameter of the global penalty term for the association parameters. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.B_tau_alphasthe prior rate parameter of the gamma prior for the precision parameter of the global penalty term for the association parameters. Only relevant when
penalty_gammas = 'ridge'orpenalty_gammas = 'horseshoe'.A_nu_alphasthe prior shape parameter of the gamma prior for the variance hyperparameter for the precision parameter of the local penalty term for the association parameters. Only relevant when
penalty_gammas = 'ridge', orpenalty_gammas = 'horseshoe'.B_nu_alphasthe prior rate parameter of the gamma prior for the variance hyperparameter for the precision parameter of the local penalty term for the association parameters. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.A_xi_alphasthe prior shape parameter of the gamma prior for the variance hyperparameter for the precision parameter of the global penalty term for the association parameters. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.B_xi_alphasthe prior rate parameter of the gamma prior for the variance hyperparameter for the precision parameter of the global penalty term for the association parameters. Only relevant when
penalty_gammas = 'ridge'or whenpenalty_gammas = 'horseshoe'.gamma_prior_D_sdslogical; if
TRUE, a gamma prior will be used for the standard deviations of the D matrix (variance-covariance matrix of the random effects). Defaults toTRUED_sds_dfthe prior degrees of freedom parameter for the half-t prior for the standard deviations of the D matrix (variance-covariance matrix of the random effects).
D_sds_sigmathe prior sigma parameter vector for the half-t prior for the standard deviations of the D matrix (variance-covariance matrix of the random effects).
D_sds_shapethe prior shape parameter for the gamma prior for the standard deviations of the D matrix (variance-covariance matrix of the random effects).
D_sds_meanthe prior mean parameter vector for the gamma prior for the standard deviations of the D matrix (variance-covariance matrix of the random effects).
D_L_etaLKJthe prior eta parameter for the LKJ prior for the correlation matrix of the random effects.
sigmas_dfthe prior degrees of freedom parameter for the half-t prior for the error term(s).
sigmas_sigmathe prior sigma parameter for the half-t prior for the error term(s).
- control
a list of control values with components:
GK_kthe number of quadrature points for the Gauss Kronrod rule; options 15 and 7.
n_chainsan integer specifying the number of chains for the MCMC. Defaults to 3.
n_burninan integer specifying the number of burn-in iterations. Defaults to 500.
n_iteran integer specifying the number of total iterations per chain. Defaults to 3500.
n_thinan integer specifying the thinning of the chains. Defaults to 1.
seedthe seed used in the sampling procedures. Defaults to 123.
MALAlogical; ifTRUE, the MALA algorithm is used when updating the elements of the Cholesky factor of the D matrix. Defaults toFALSE.save_random_effectslogical; ifTRUE, the full MCMC results of the random effects will be saved and returned with thejmobject. Defaults toFALSE.save_logLik_contributionslogical; ifTRUE, the log-likelihood contributions are saved in themcmccomponent of thejmobject. Defaults toFALSEcoresan integer specifying the number of cores to use for running the chains in parallel; no point of setting this greater than
n_chains.parallela character string indicating how the parallel sampling of the chains will be performed. Options are
"snow"(default) and"multicore".basischaracter string with possible values
"bs"(default) or"ns". When"bs"a B-spline basis is used to approximate the log baseline hazard function with degree of the spline specified by theBsplines_degree. When"ns"a natrual cubic spline basis is used; in this case the value of theBsplines_degreecontrol argument is ignored.Bsplines_degreethe degree of the splines in each basis; default is quadratic splines.
base_hazard_segmentsthe number of segments to split the follow-up period for the spline approximation of the log baseline hazard function. Defaults to 10.
timescale_base_hazardcharacter string with possible values
"identity"(default) or"log". When"identity"the spline basis is specified for the time variable in its orginal scale. When"log"the spline basis is specified for the logarithm of the time variable.diffthe order of the difference used in the penalty matrix for the coefficients of the splines used to approximate the log baseline hazard function. Defaults to 2.
knotsa numeric vector with the position of the knots for the spline approximation of the log baseline hazard function. The default is equally-spaced knots starting from
sqrt(.Machine$double.eps)until the maximum follow-up time.
- x
a numeric input variable.
- knots
a numeric vector of knots.
- ord
an integer denoting the order of the spline.
- zero_ind
a list with integer vectors indicating which coefficients are set to zero in the calculation of the value term. This can be used to include for example only the random intercept; default is
NULL.- eps
numeric scalar denoting the step-size for the finite difference approximation.
- direction
character string for the direction of the numerical derivative, options are
"both", and"backward".- time_window
numeric scalar controlling the time window used by the
Delta()andarea()functional forms. Forarea(),time_windowspecifies the lower limit of the interval over which the integral is evaluated. ForDelta(),time_windowspecifies the length of the time interval (i.e., the contrast between t and t -time_window) over which the finite difference is computed; when set toNULL(the default), the contrast is taken between the current time and time 0.- standardise
logical; controls whether theDelta()functional form returns a rate or a raw contrast. IfTRUE, the difference between the values at the two time points is divided by the time distance between them, yielding a change per unit time. IfFALSE,Delta()returns the raw difference over the specified time window. Defaults toFALSE.- IE_time
a
characterstring specifying the name of the intermediate event time variable in thedata.frameused to fit the Cox/AFT survival submodel. For groups/subjects who did not experience the intermediate event, the time should be set toInf. The sameIE_timevariable should be used when specifying multiple functional forms for the same longitudinal outcome.- ...
arguments passed to
control.
Details
The mathematical details regarding the definition of the multivariate joint model, and the capabilities of the package can be found in the vignette in the doc directory.
Notes:
The ordering of the subjects in the datasets used to fit the mixed and Cox regression models needs to be the same.
The units of the time variables in the mixed and Cox models need to be the same.
Value
A list of class jm with components:
- mcmc
a
listof the MCMC samples for each parameter.- acc_rates
a
listof the acceptance rates for each parameter.- logLik
a
matrixof dimensions [((n_iter - n_burnin)/n_thin)*n_thin, number of individuals], with element [i, j] being the conditional log-Likelihood value of the \(i^{th}\) iteration for the \(j^{th}\) individual.- mlogLik
a
matrixof dimensions [((n_iter - n_burnin)/n_thin)*n_thin, number of individuals], with element [i, j] being the marginal log-Likelihood value of the \(i^{th}\) iteration for the \(j^{th}\) individual.- running_time
an object of class
proc_timewith the time used to runjm.- statistics
a
listwith posterior estimates of the parameters (means, medians, standard deviations, standard errors, effective sample sizes, tail probabilities, upper and lower bounds of credible intervals, etc.).- fit_stats
a
listof lists with fit statistics (DIC, pD, LPML, CPO, WAIC) for both conditional and marginal formulations.- model_data
a
listof data used to fit the model.- model_info
a
listof components of the fit useful to other functions.- initial_values
a
listwith the initial values of the parameters.- control
a copy of the
controlvalues used to fit the model.- priors
a copy of the
priorsused to fit the model.- call
the matched call.
Author
Dimitris Rizopoulos d.rizopoulos@erasmusmc.nl
Examples
# \donttest{
################################################################################
##############################################
# Univariate joint model for serum bilirubin #
# 1 continuous outcome #
##############################################
# [1] Fit the mixed model using lme().
fm1 <- lme(fixed = log(serBilir) ~ year * sex + I(year^2) +
age + prothrombin, random = ~ year | id, data = pbc2)
# [2] Fit a Cox model, specifying the baseline covariates to be included in the
# joint model.
fCox1 <- coxph(Surv(years, status2) ~ drug + age, data = pbc2.id)
# [3] The basic joint model is fitted using a call to jm() i.e.,
joint_model_fit_1 <- jm(fCox1, fm1, time_var = "year",
n_chains = 1L, n_iter = 11000L, n_burnin = 1000L)
summary(joint_model_fit_1)
#>
#> Call:
#> JMbayes2::jm(Surv_object = fCox1, Mixed_objects = fm1, time_var = "year",
#> n_chains = 1L, n_iter = 11000L, n_burnin = 1000L)
#>
#> Data Descriptives:
#> Number of Groups: 312 Number of events: 140 (44.9%)
#> Number of Observations:
#> log(serBilir): 1945
#>
#> DIC WAIC LPML
#> marginal 4204.643 5075.364 -2931.823
#> conditional 3334.409 3165.829 -1817.475
#>
#> Random-effects covariance matrix:
#>
#> StdDev Corr
#> (Intr) 0.9752 (Intr)
#> year 0.1772 0.3429
#>
#> Survival Outcome:
#> Mean StDev 2.5% 97.5% P
#> drugD-penicil -0.0294 0.2359 -0.4760 0.4417 0.913
#> age 0.0639 0.0092 0.0465 0.0824 0.000
#> value(log(serBilir)) 1.4254 0.0976 1.2296 1.6264 0.000
#>
#> Longitudinal Outcome: log(serBilir) (family = gaussian, link = identity)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) 0.2444 0.3605 -0.4688 0.9355 0.4880
#> year 0.2281 0.0370 0.1568 0.3005 0.0000
#> sexfemale -0.2421 0.1816 -0.6013 0.1134 0.1850
#> I(year^2) 0.0026 0.0010 0.0007 0.0045 0.0066
#> age -0.0017 0.0054 -0.0122 0.0092 0.7452
#> prothrombin 0.0529 0.0085 0.0364 0.0695 0.0000
#> year:sexfemale -0.0881 0.0385 -0.1644 -0.0137 0.0206
#> sigma 0.3452 0.0068 0.3322 0.3594 0.0000
#>
#> MCMC summary:
#> chains: 1
#> iterations per chain: 11000
#> burn-in per chain: 1000
#> thinning: 1
#> time: 33 sec
traceplot(joint_model_fit_1)
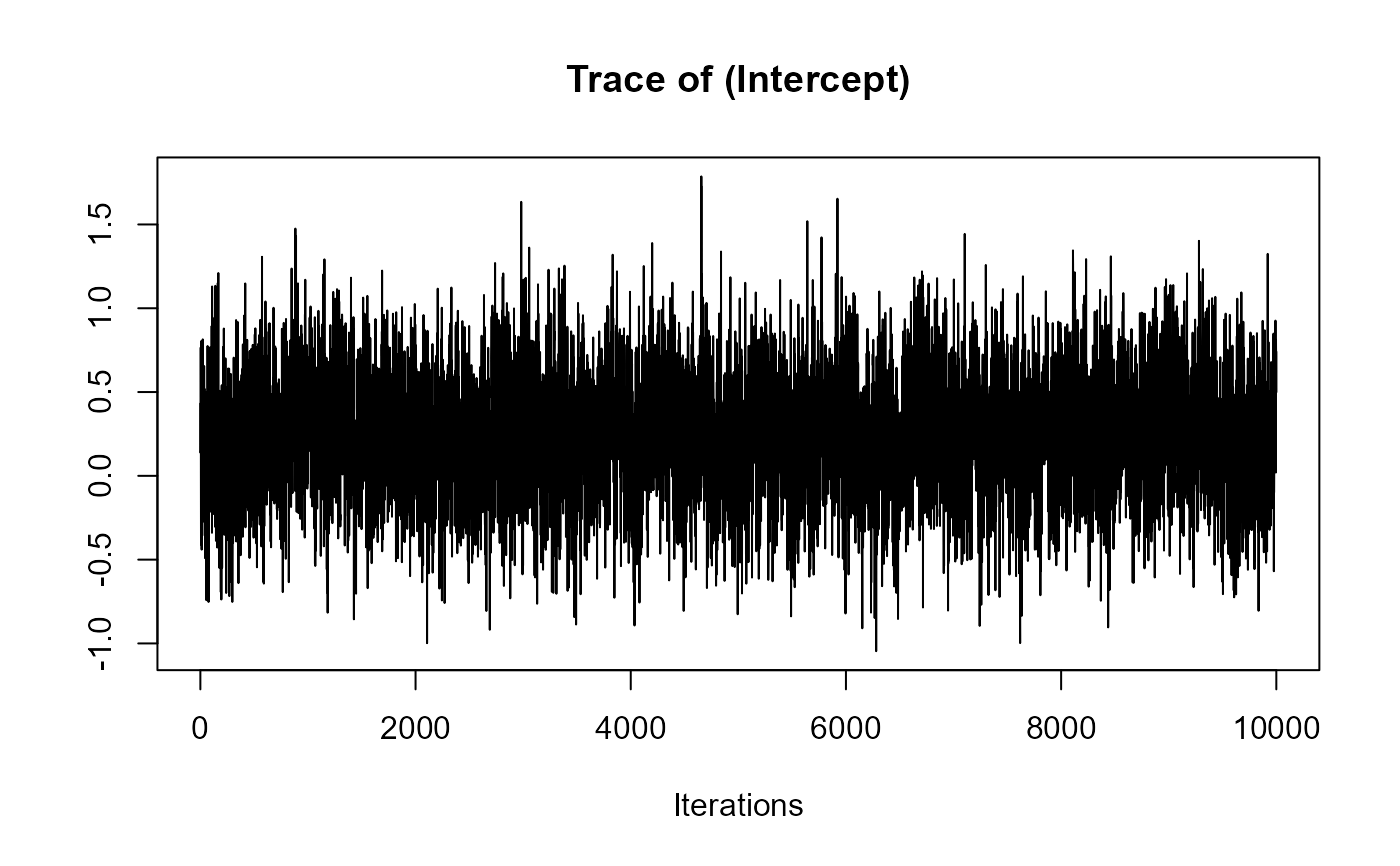
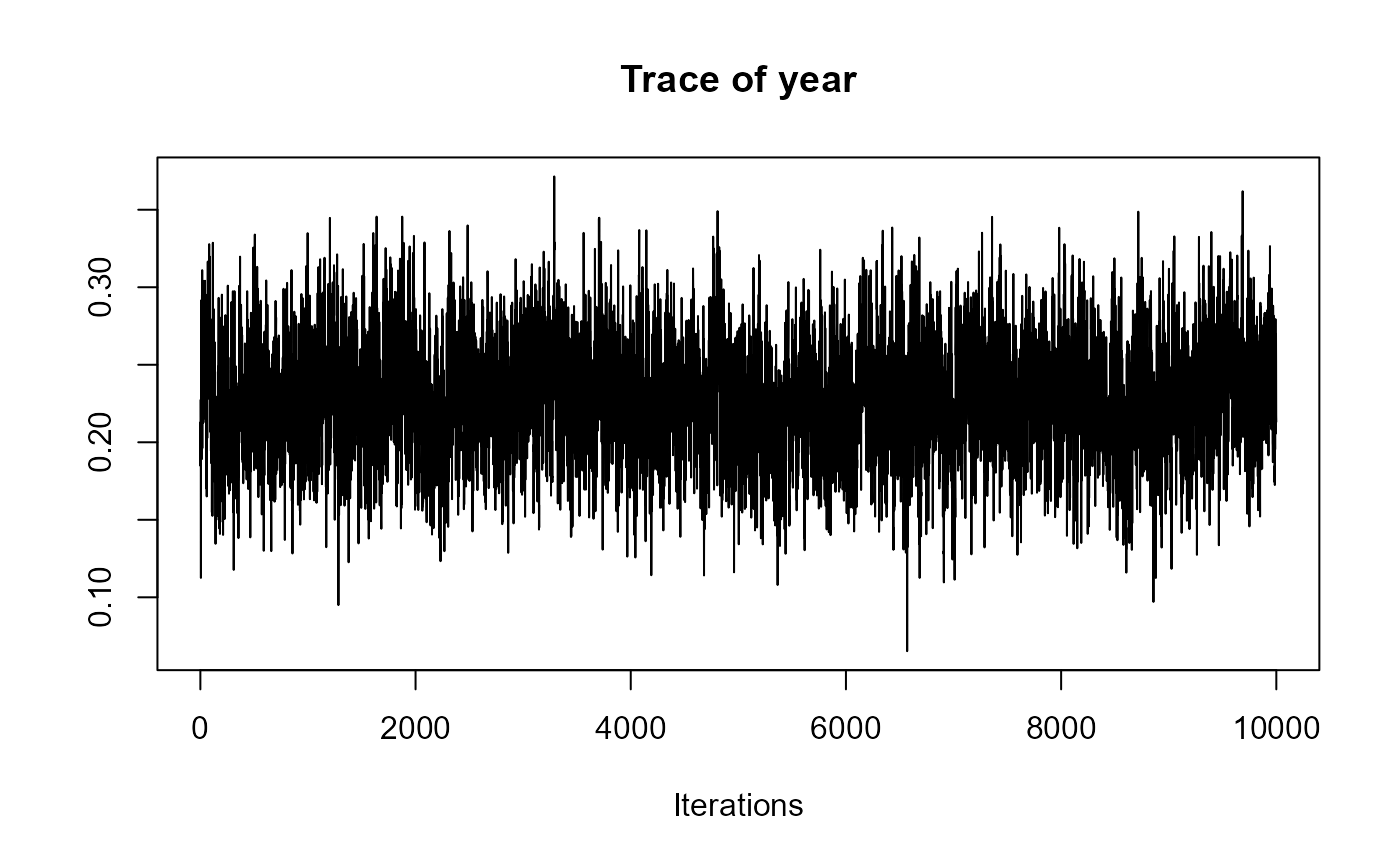
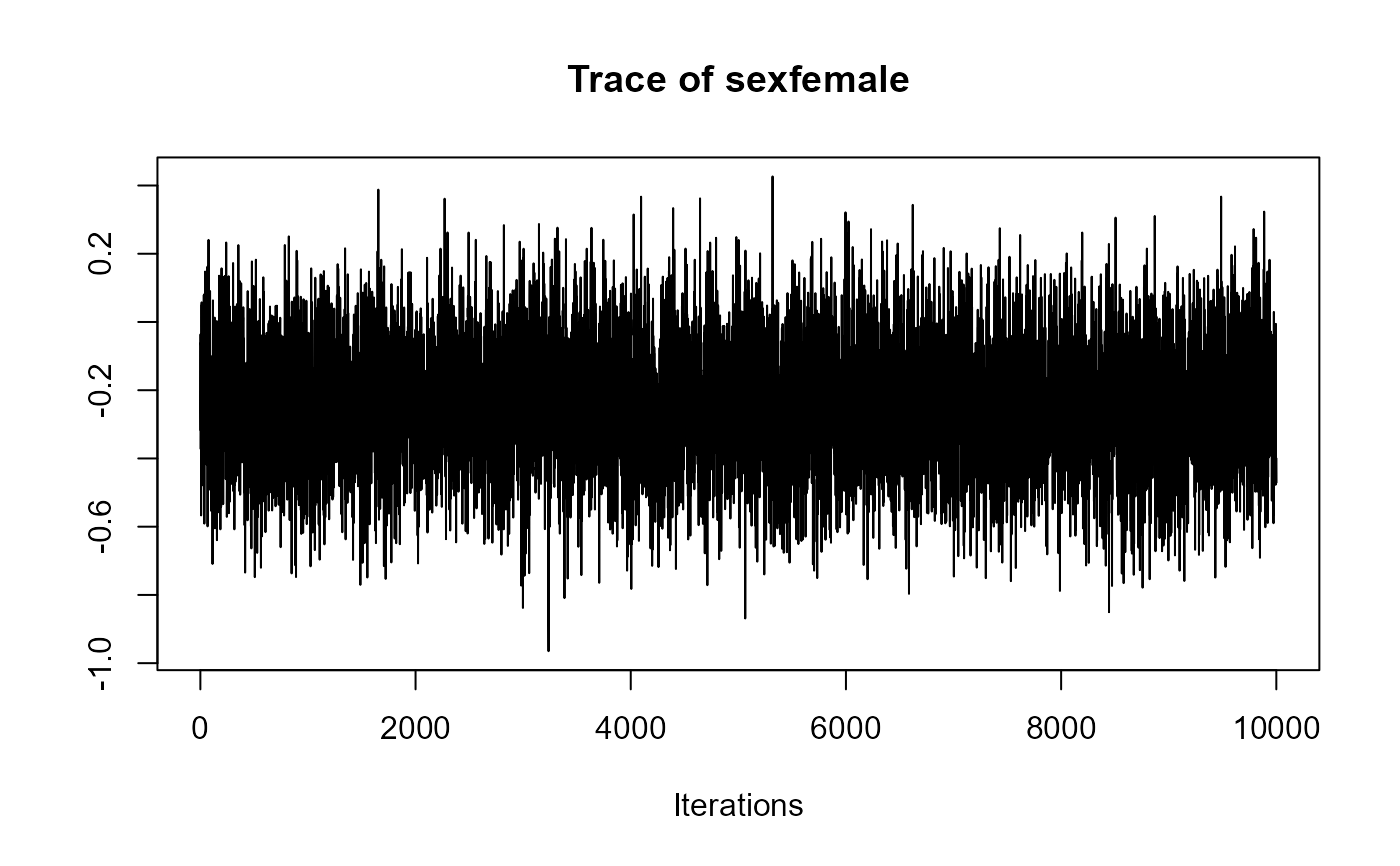
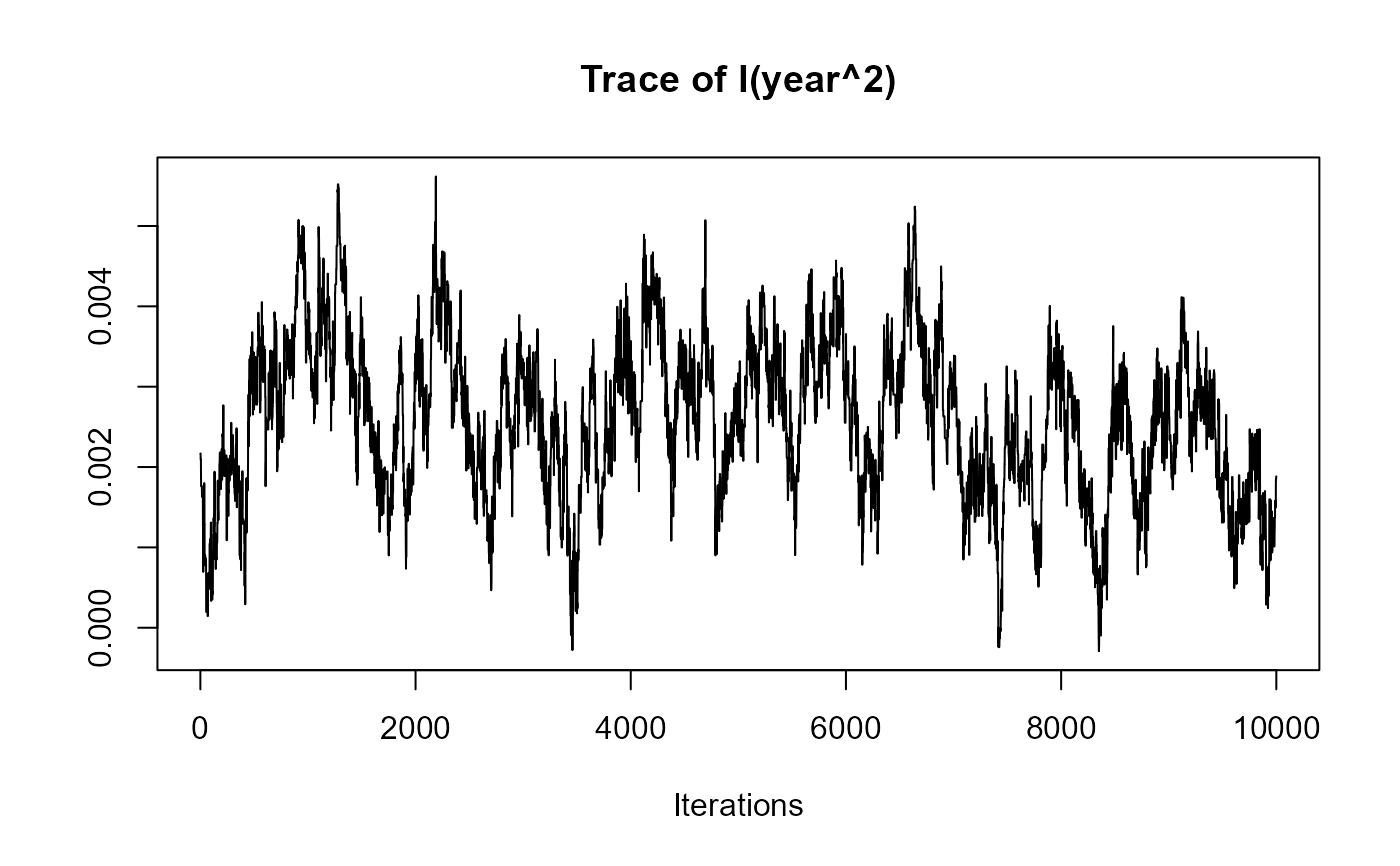
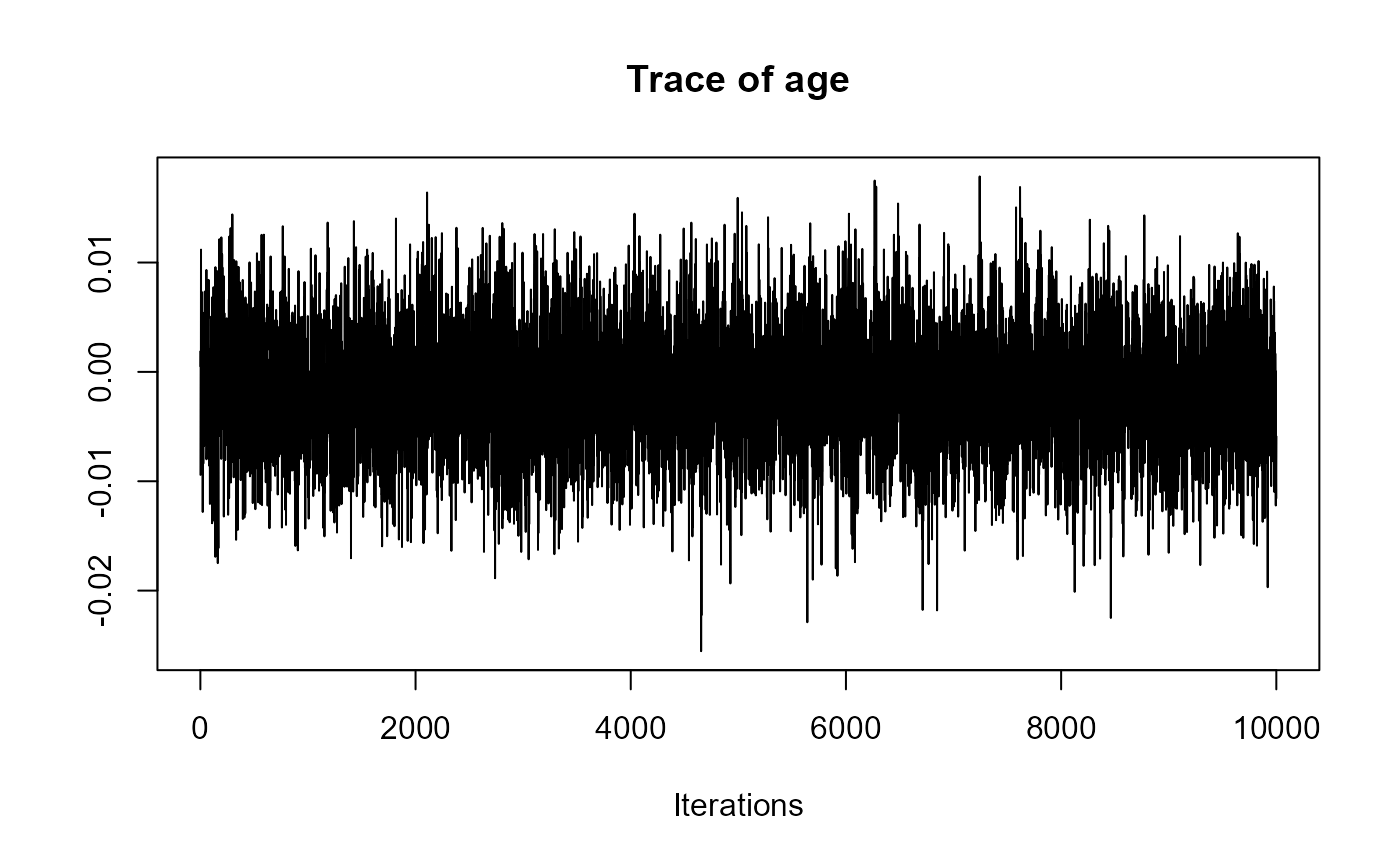
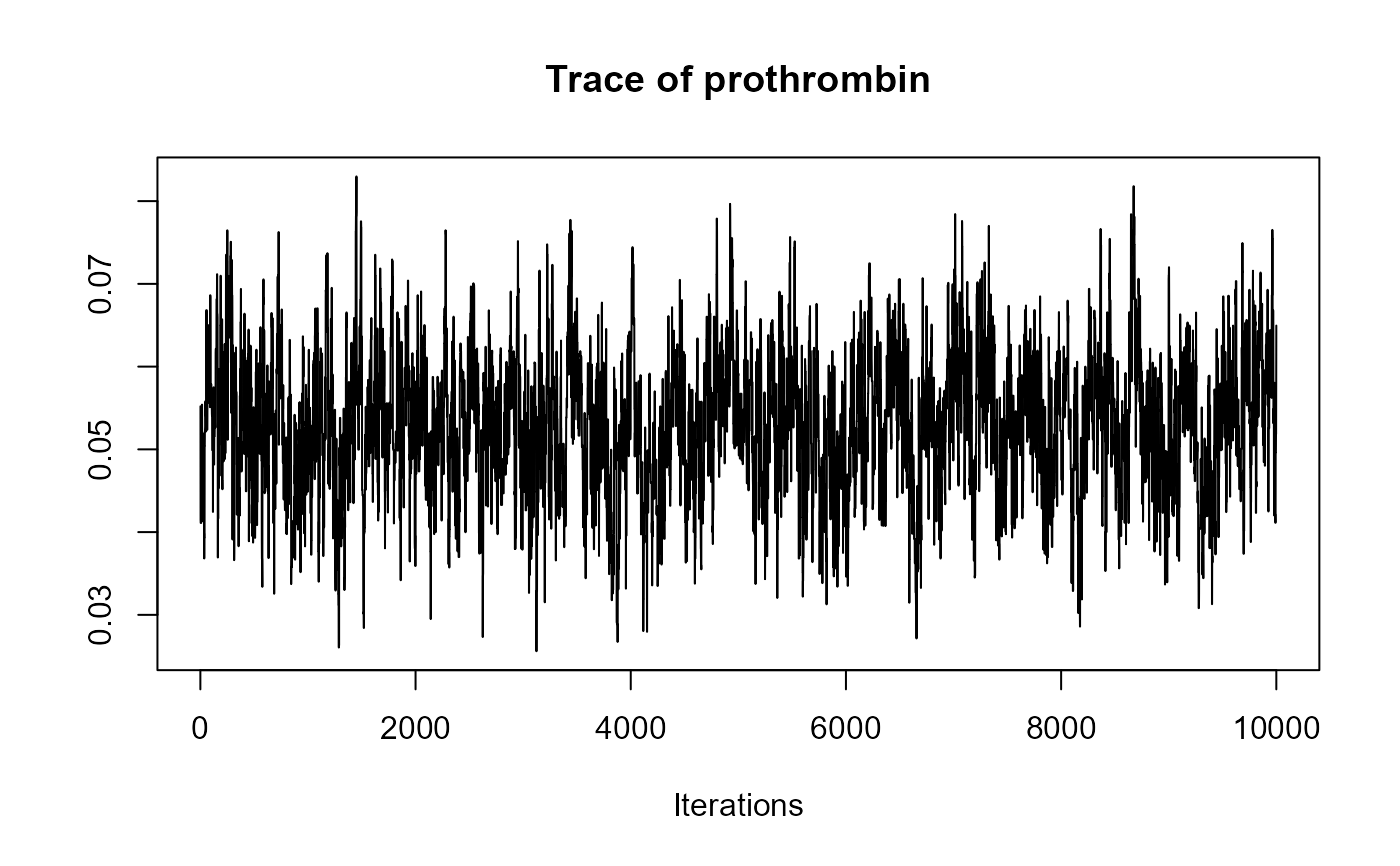
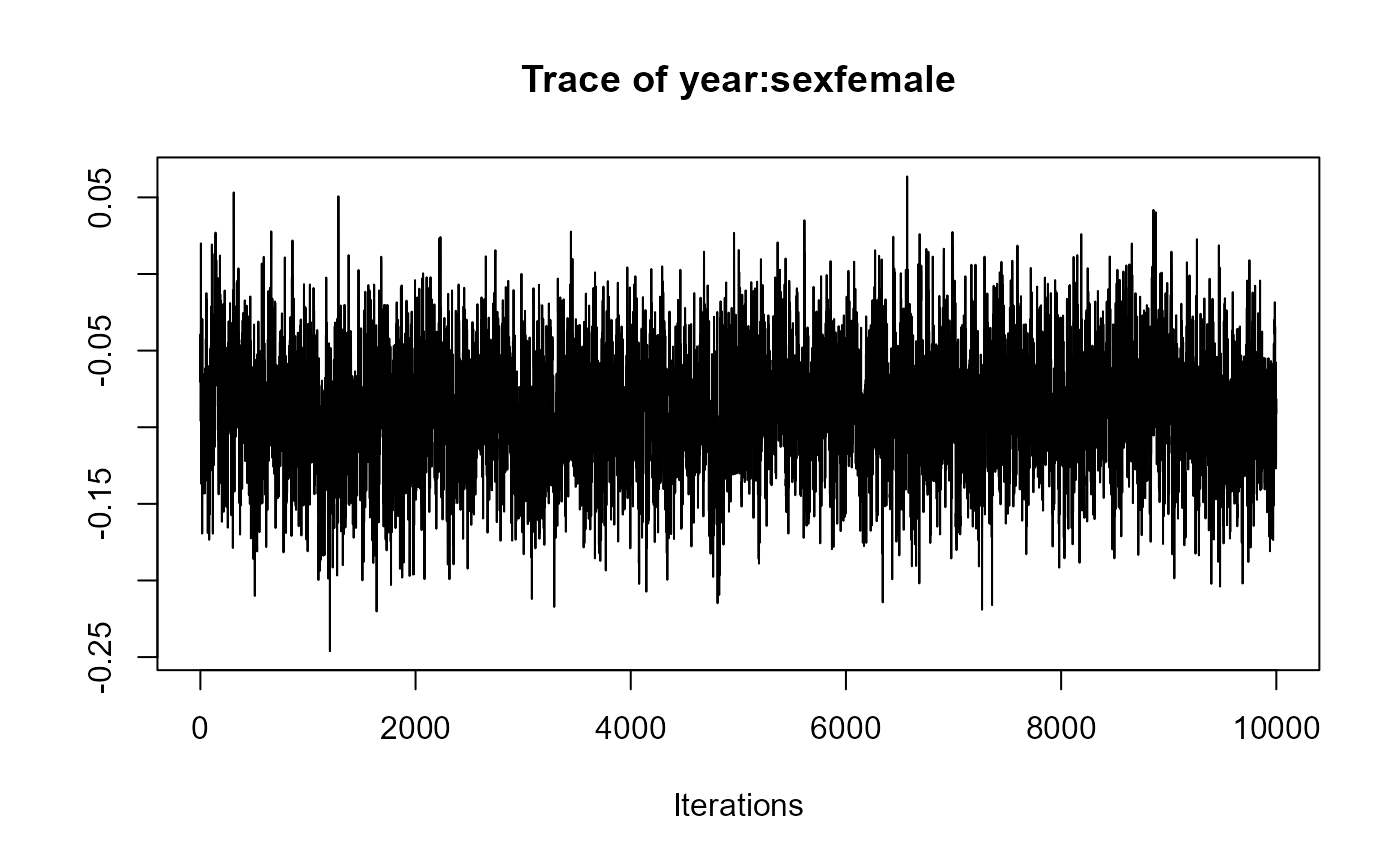
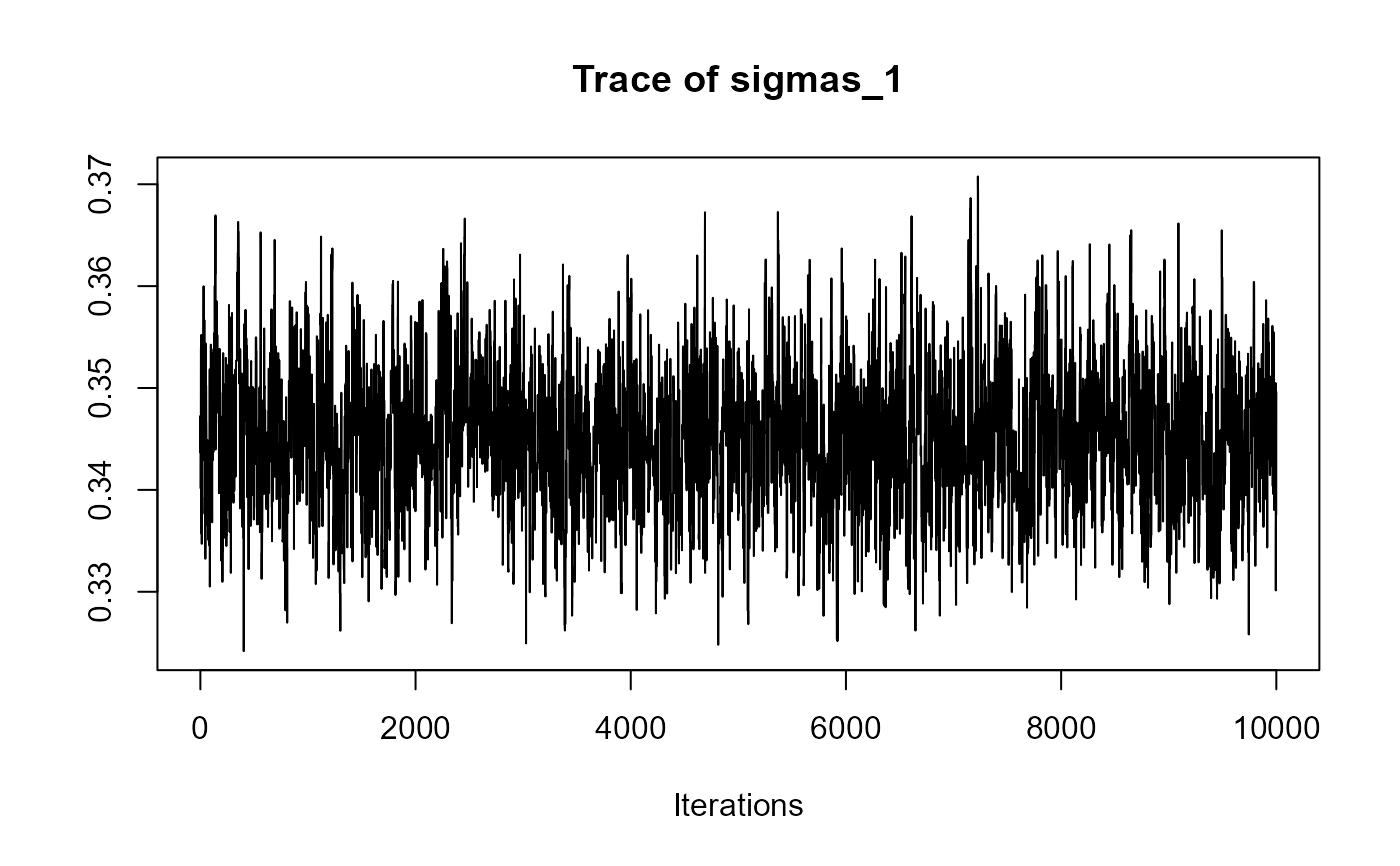
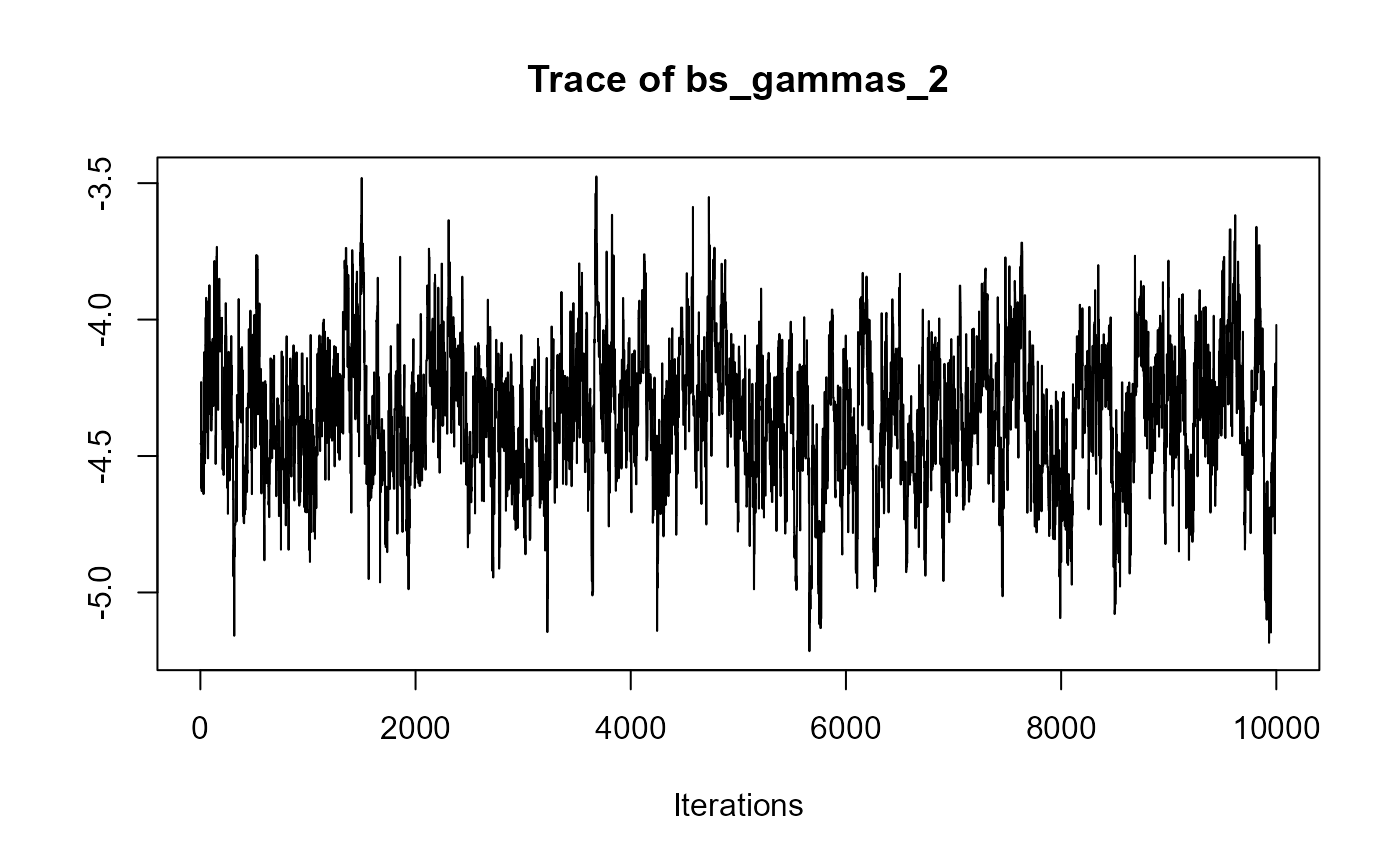
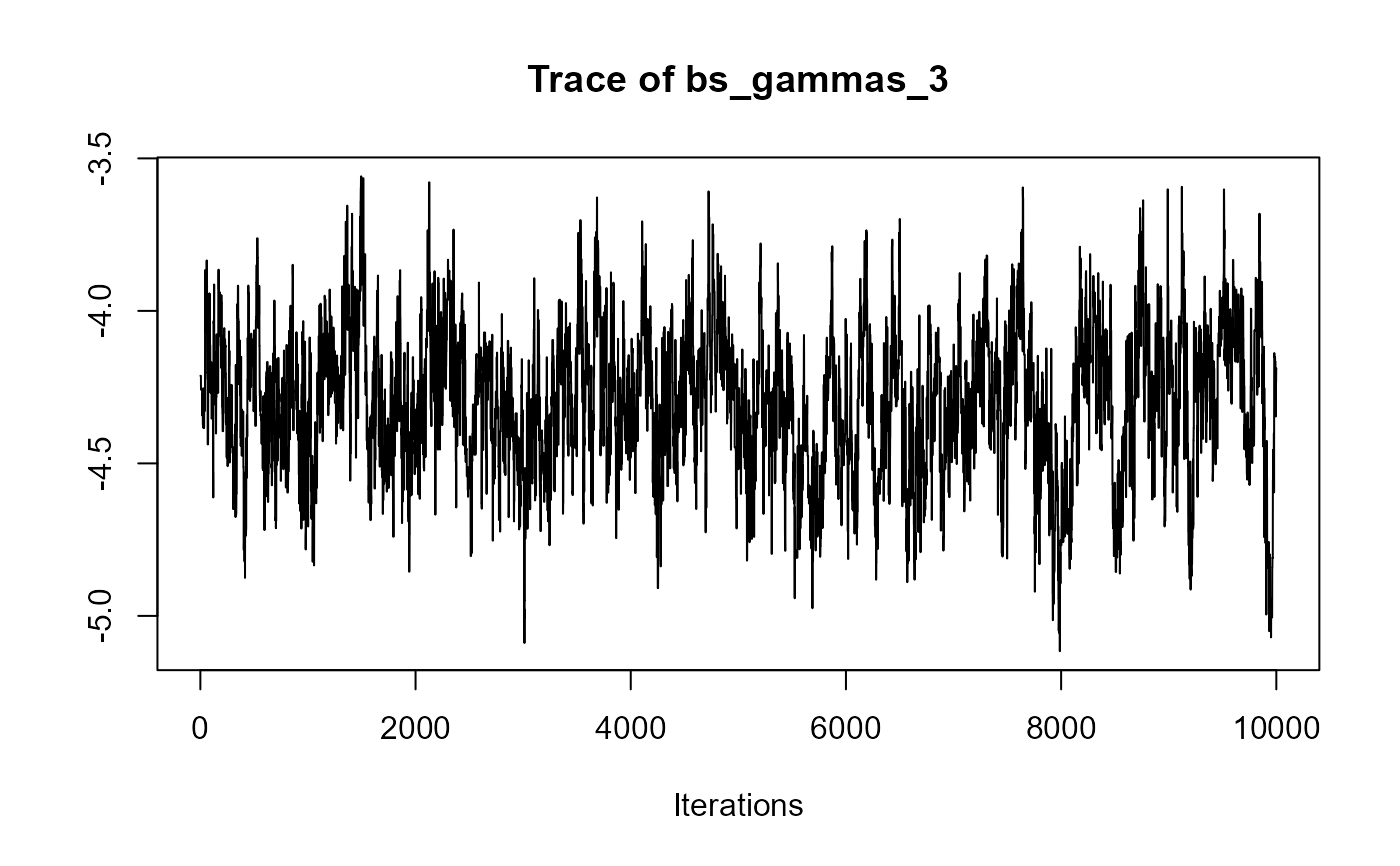
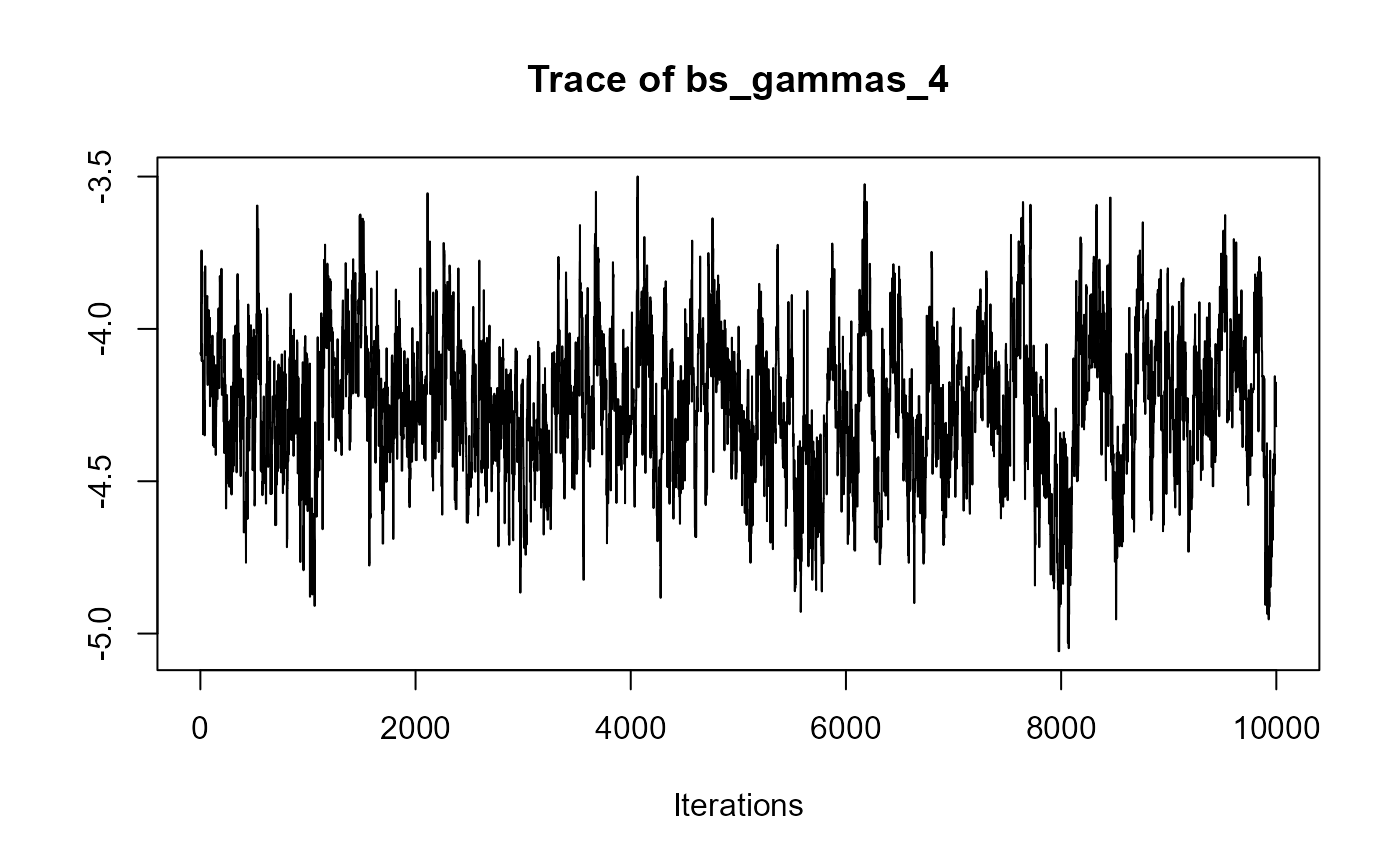
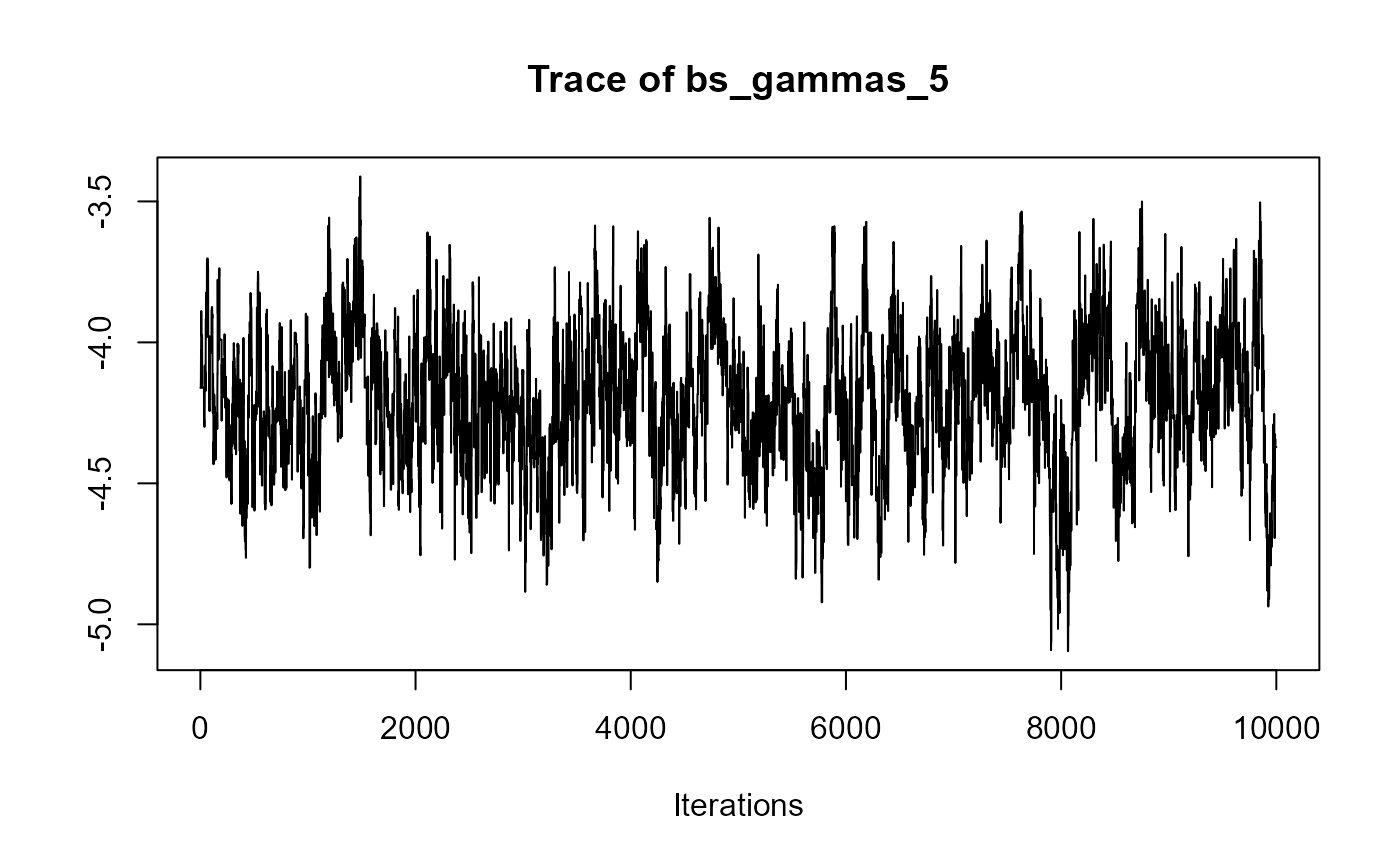
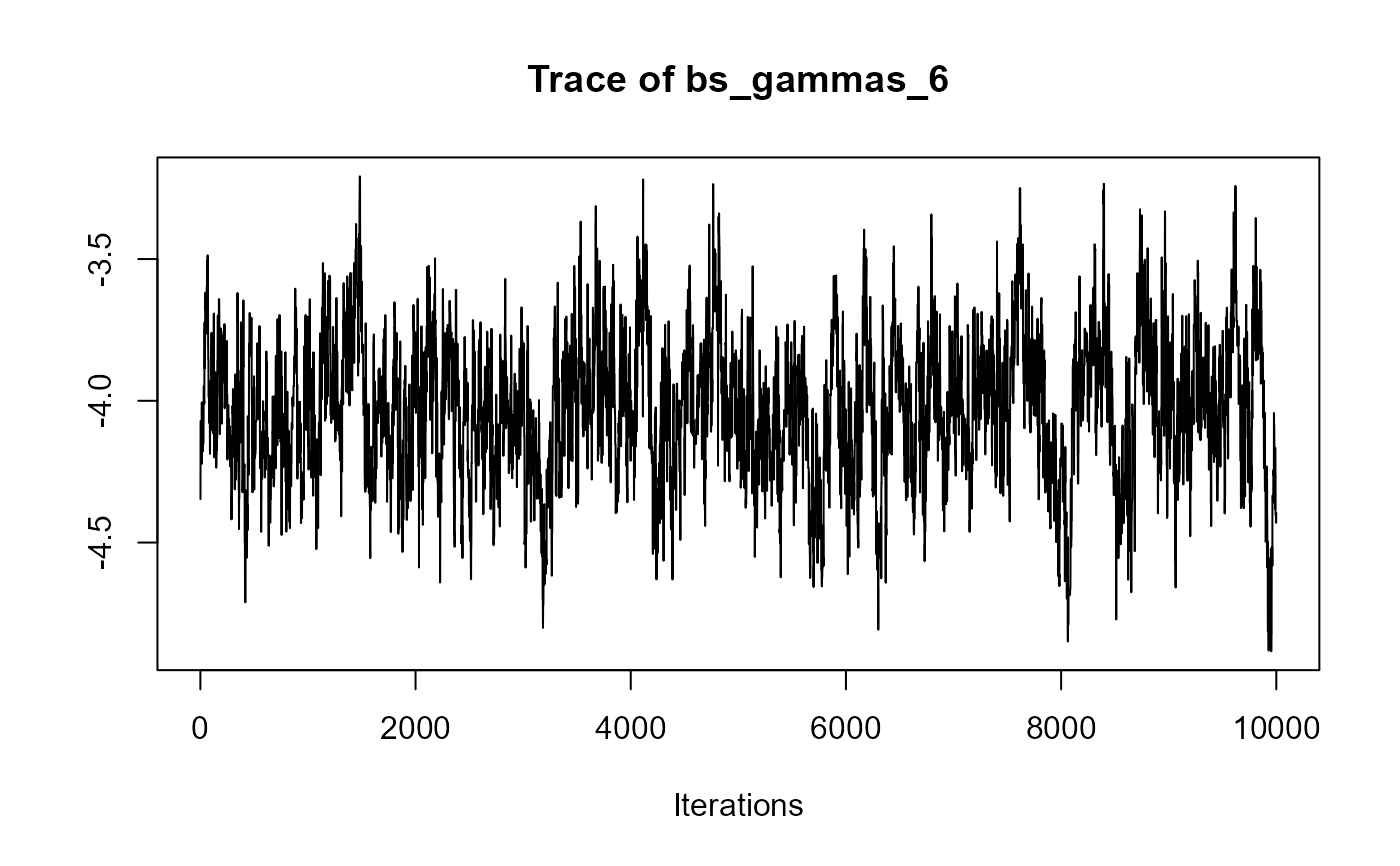
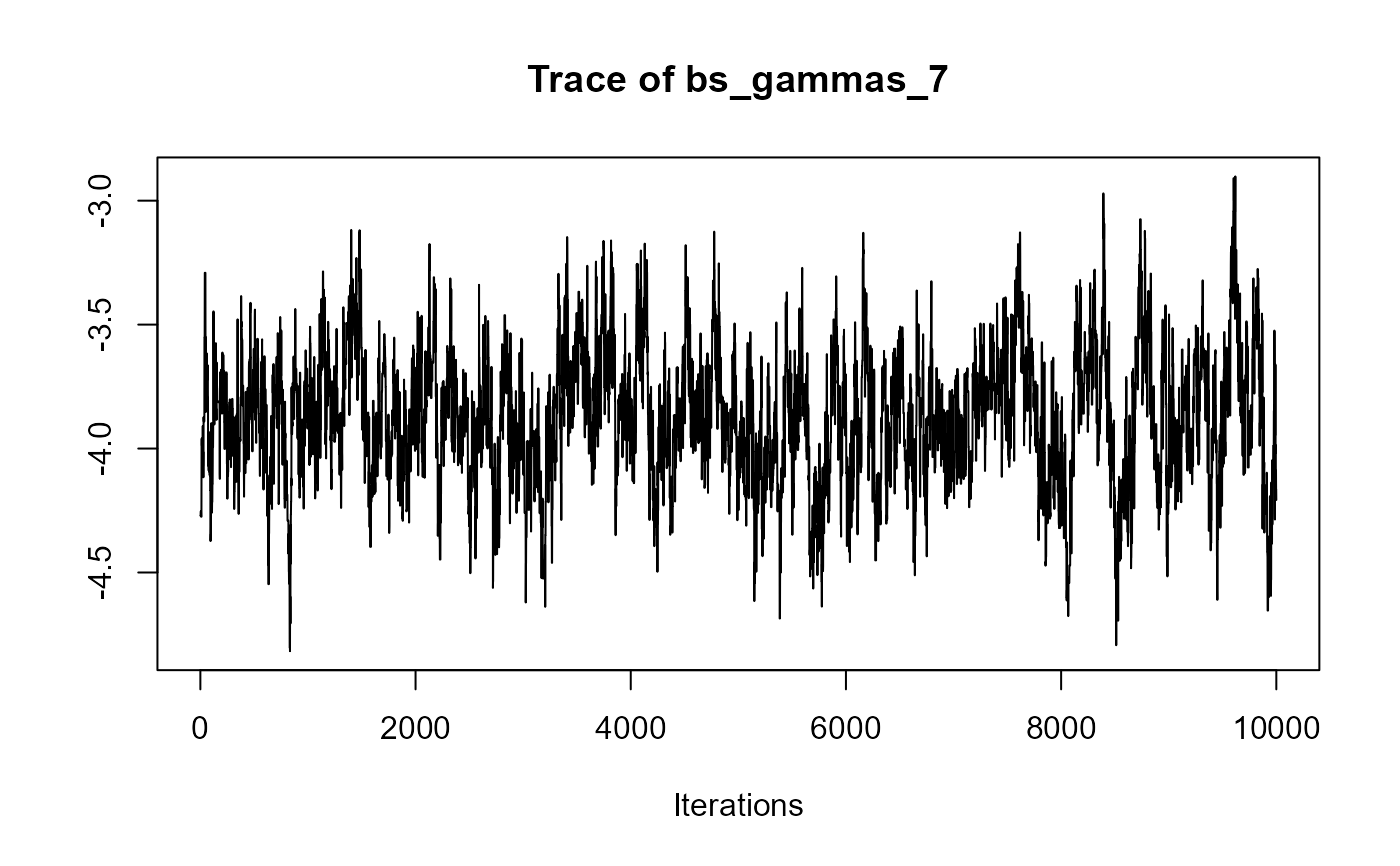
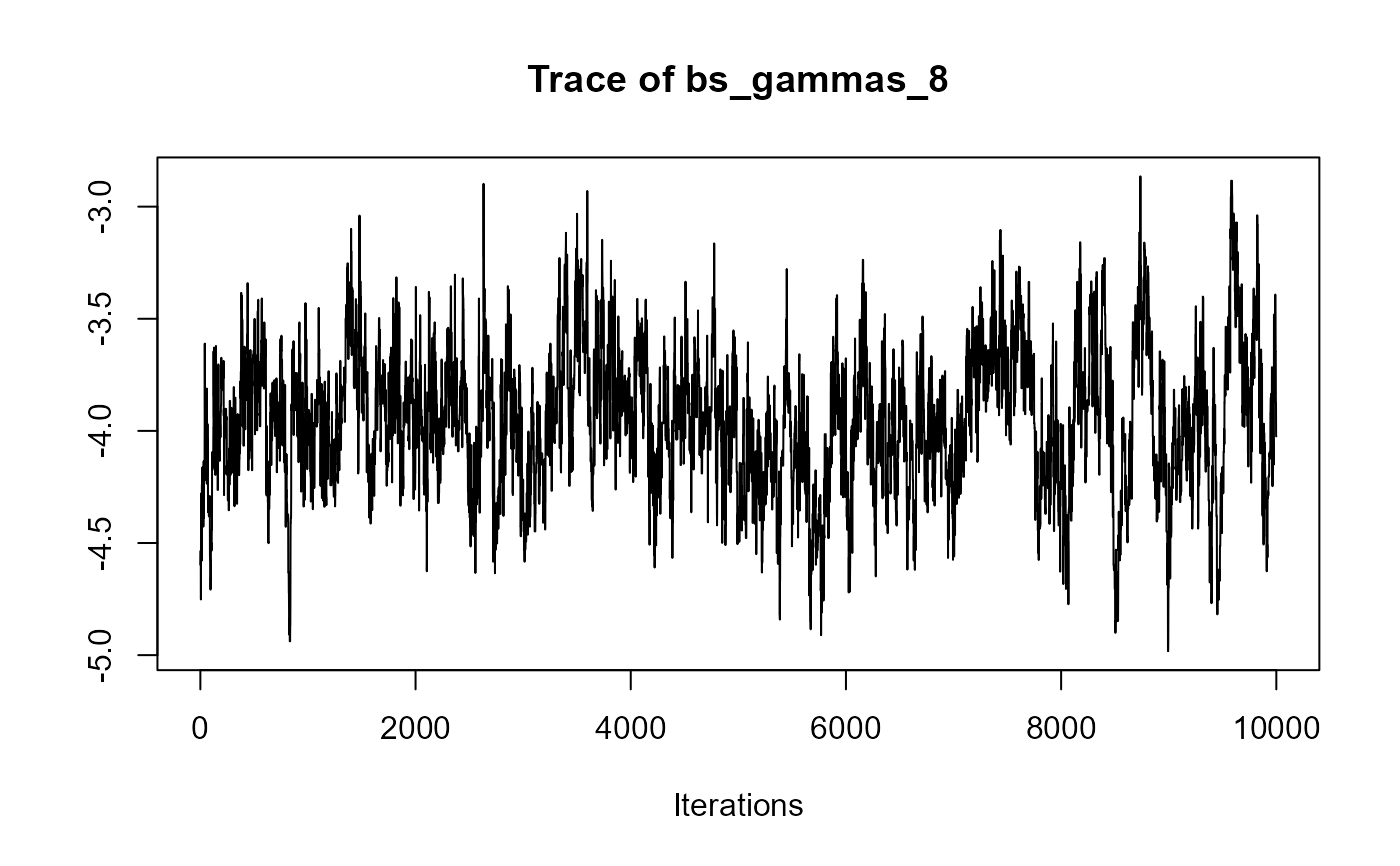
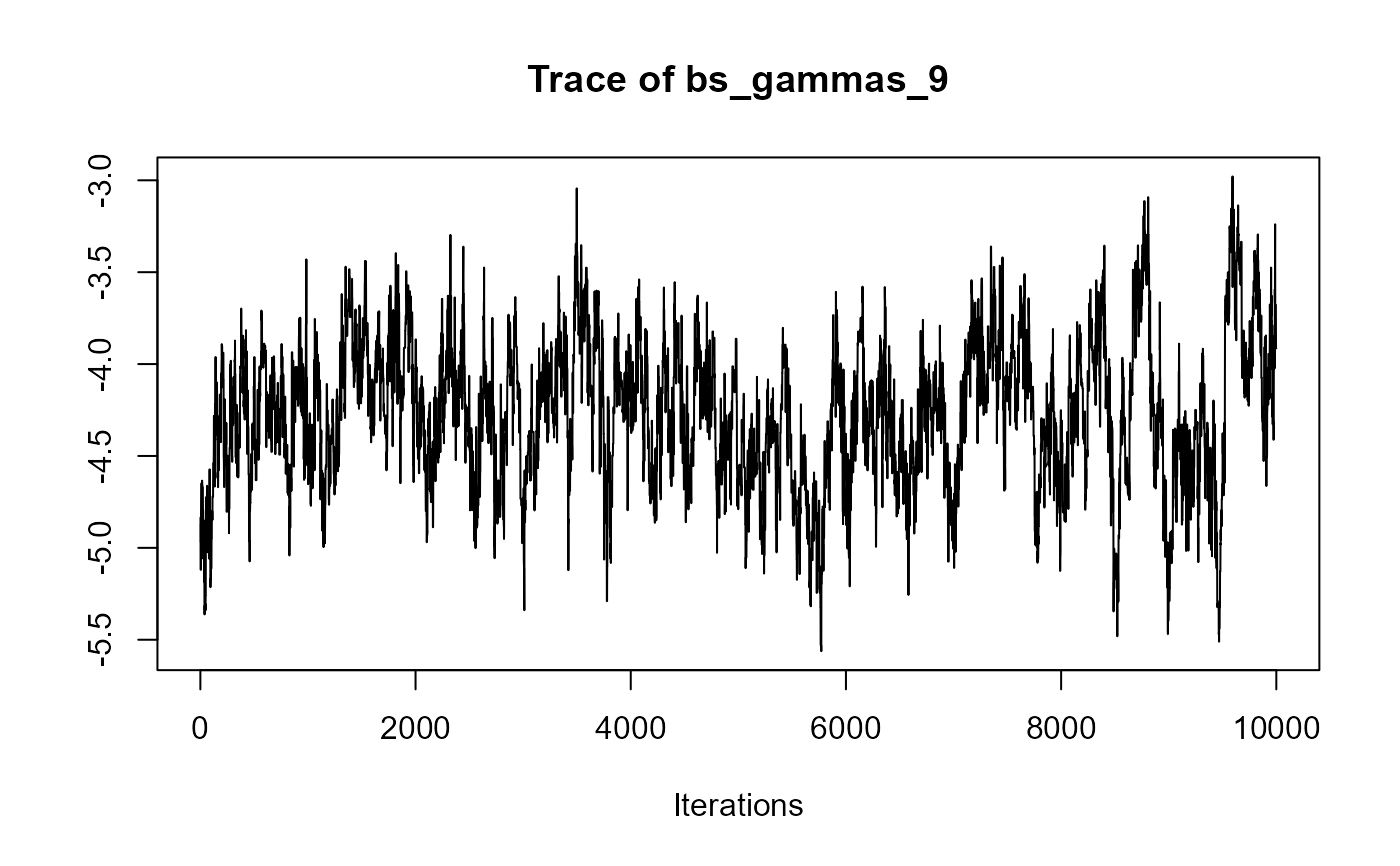
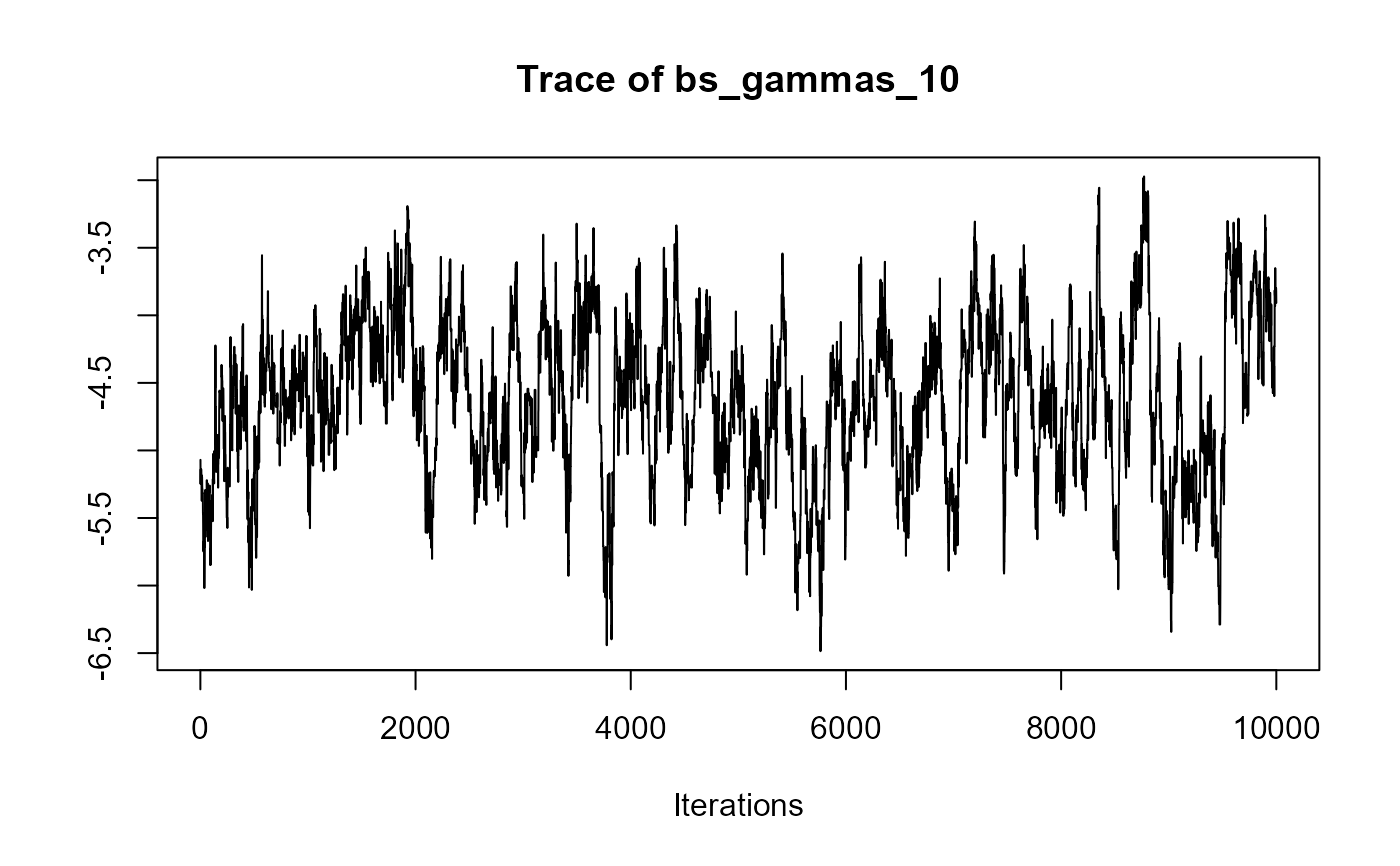
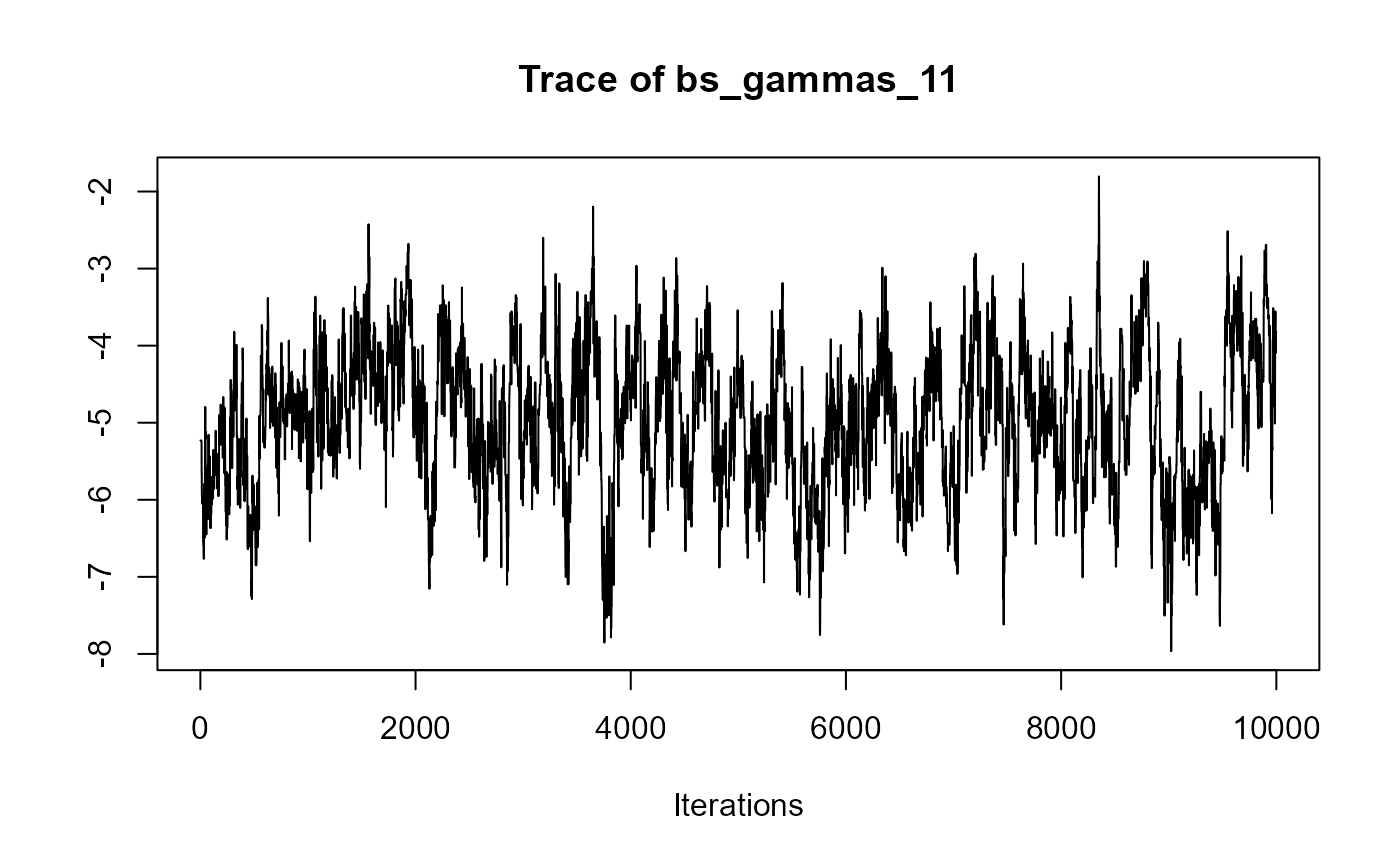
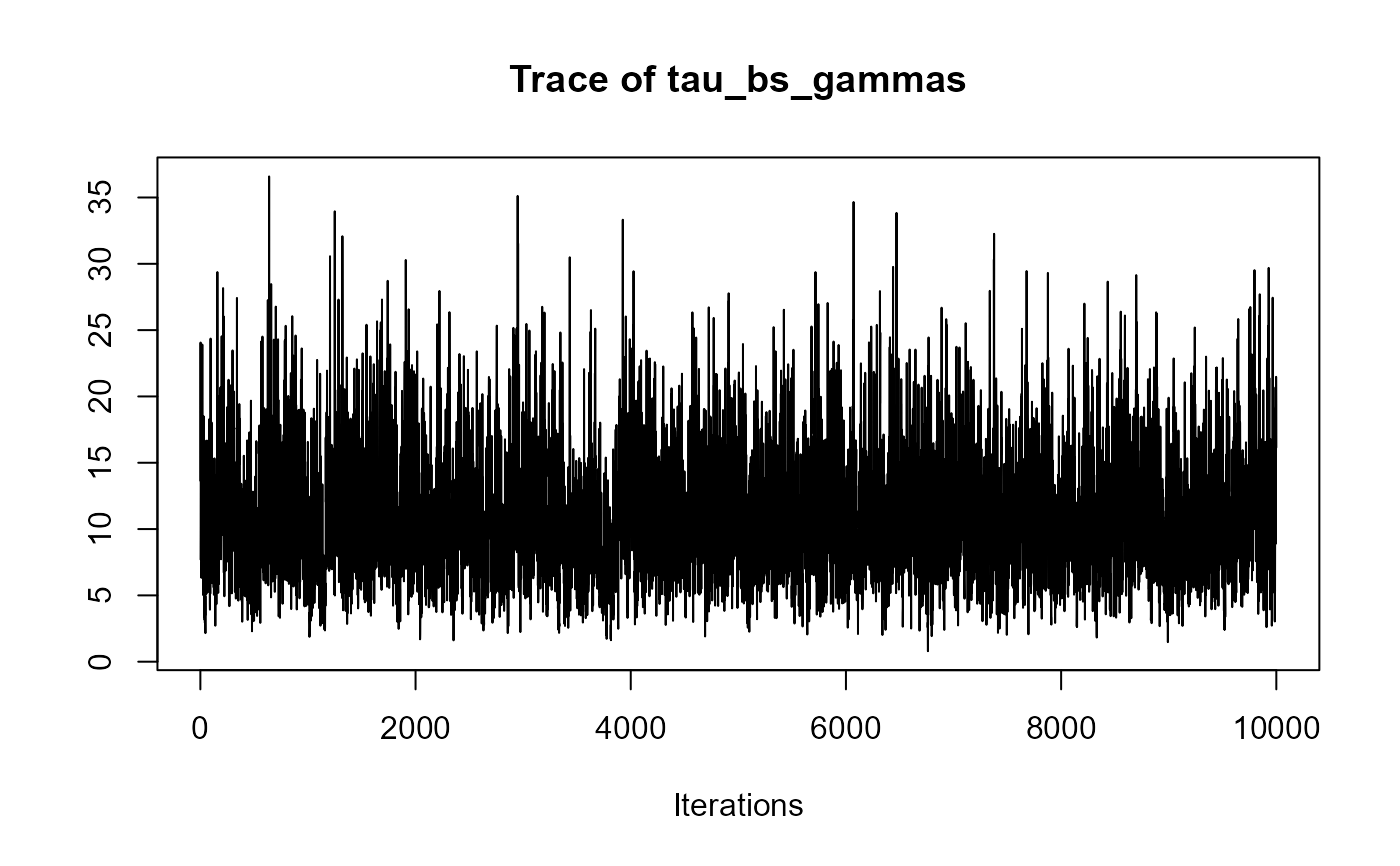
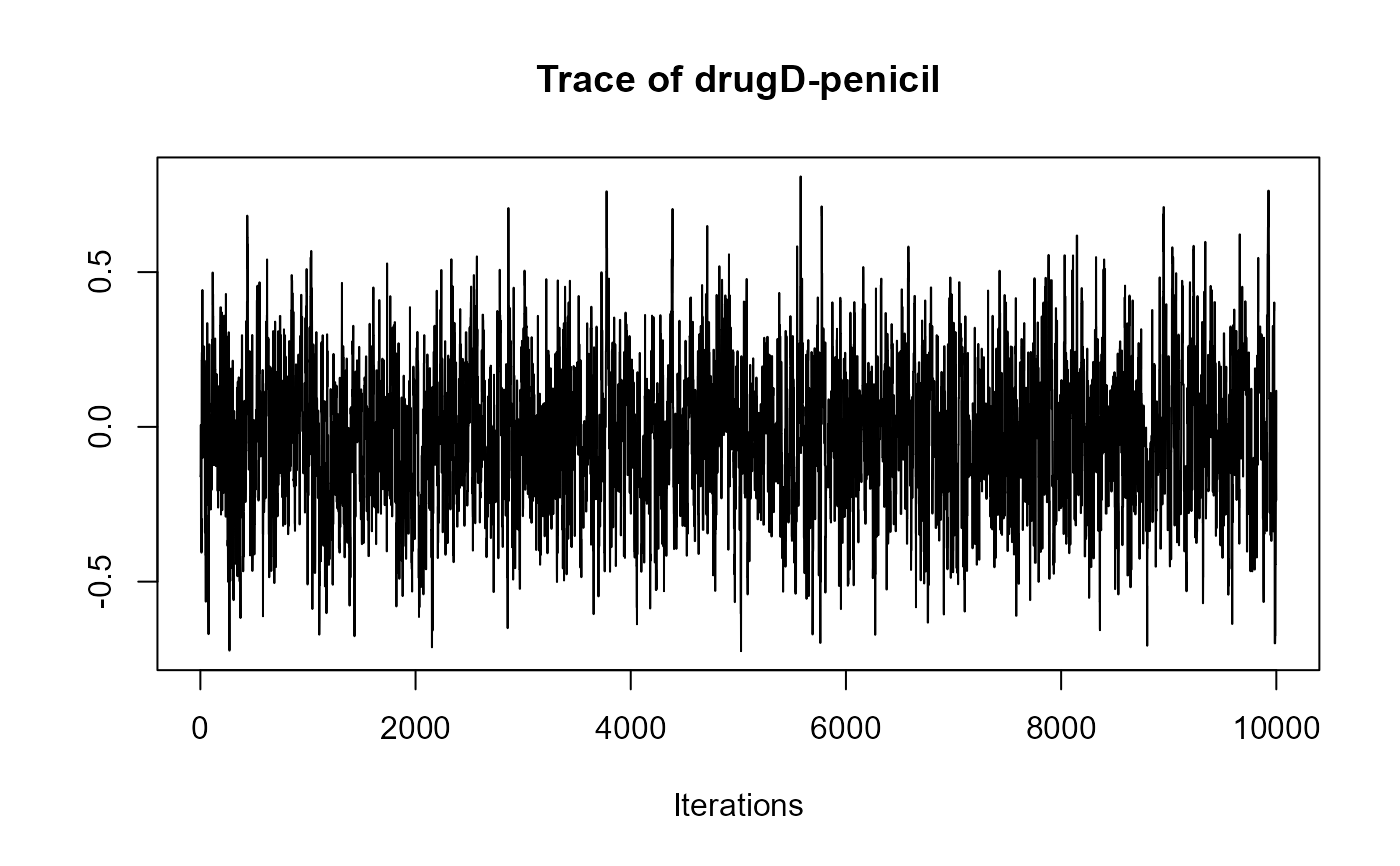
 ################################################################################
##########################################################################
# Multivariate joint model for serum bilirubin, hepatomegaly and ascites #
# 1 continuous outcome, 2 categorical outcomes #
##########################################################################
# [1] Fit the mixed-effects models using lme() for continuous
# outcomes and mixed_model() for categorical outcomes.
fm1 <- lme(fixed = log(serBilir) ~ year * sex,
random = ~ year | id, data = pbc2)
fm2 <- mixed_model(hepatomegaly ~ sex + age + year, data = pbc2,
random = ~ year | id, family = binomial())
fm3 <- mixed_model(ascites ~ year + age, data = pbc2,
random = ~ year | id, family = binomial())
# [2] Save all the fitted mixed-effects models in a list.
Mixed <- list(fm1, fm2, fm3)
# [3] Fit a Cox model, specifying the baseline covariates to be included in the
# joint model.
fCox1 <- coxph(Surv(years, status2) ~ drug + age, data = pbc2.id)
# [4] The joint model is fitted using a call to jm() i.e.,
joint_model_fit_2 <- jm(fCox1, Mixed, time_var = "year",
n_chains = 1L, n_iter = 11000L, n_burnin = 1000L)
summary(joint_model_fit_2)
#>
#> Call:
#> JMbayes2::jm(Surv_object = fCox1, Mixed_objects = Mixed, time_var = "year",
#> n_chains = 1L, n_iter = 11000L, n_burnin = 1000L)
#>
#> Data Descriptives:
#> Number of Groups: 312 Number of events: 140 (44.9%)
#> Number of Observations:
#> log(serBilir): 1945
#> hepatomegaly: 1884
#> ascites: 1885
#>
#> DIC WAIC LPML
#> marginal 6642.124 6855.619 -3657.905
#> conditional 9083.033 8826.991 -4889.348
#>
#> Random-effects covariance matrix:
#>
#> StdDev Corr
#> (Intr) 0.9912 (Intr) year (Intr) year (Intr)
#> year 0.1757 0.3802
#> (Intr) 3.2808 0.5267 0.3405
#> year 0.5670 0.0444 0.3482 -0.3466
#> (Intr) 2.8763 0.6201 0.4974 0.5264 -0.0074
#> year 0.4205 0.3543 0.6047 0.3516 0.2719 -0.0672
#>
#> Survival Outcome:
#> Mean StDev 2.5% 97.5% P
#> drugD-penicil -0.1890 0.2679 -0.7106 0.3437 0.4658
#> age 0.0330 0.0143 0.0032 0.0584 0.0316
#> value(log(serBilir)) 0.7016 0.2205 0.2706 1.1292 0.0084
#> value(hepatomegaly) -0.0515 0.0829 -0.2015 0.1152 0.5190
#> value(ascites) 0.5672 0.2027 0.2048 1.0108 0.0000
#>
#> Longitudinal Outcome: log(serBilir) (family = gaussian, link = identity)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) 0.6726 0.1405 0.3984 0.9542 0.0000
#> year 0.2465 0.0276 0.1933 0.3007 0.0000
#> sexfemale -0.2054 0.1446 -0.4946 0.0722 0.1492
#> year:sexfemale -0.0649 0.0283 -0.1209 -0.0106 0.0186
#> sigma 0.3479 0.0068 0.3351 0.3620 0.0000
#>
#> Longitudinal Outcome: hepatomegaly (family = binomial, link = logit)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) 0.0769 1.0083 -1.8713 2.0778 0.9420
#> sexfemale -0.7586 0.5246 -1.8069 0.2517 0.1386
#> age 0.0146 0.0162 -0.0175 0.0466 0.3664
#> year 0.2461 0.0689 0.1083 0.3800 0.0000
#>
#> Longitudinal Outcome: ascites (family = binomial, link = logit)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) -9.0119 1.0153 -11.1983 -7.1497 0
#> year 0.5763 0.0687 0.4611 0.7208 0
#> age 0.0811 0.0160 0.0507 0.1152 0
#>
#> MCMC summary:
#> chains: 1
#> iterations per chain: 11000
#> burn-in per chain: 1000
#> thinning: 1
#> time: 1.3 min
traceplot(joint_model_fit_2)
################################################################################
##########################################################################
# Multivariate joint model for serum bilirubin, hepatomegaly and ascites #
# 1 continuous outcome, 2 categorical outcomes #
##########################################################################
# [1] Fit the mixed-effects models using lme() for continuous
# outcomes and mixed_model() for categorical outcomes.
fm1 <- lme(fixed = log(serBilir) ~ year * sex,
random = ~ year | id, data = pbc2)
fm2 <- mixed_model(hepatomegaly ~ sex + age + year, data = pbc2,
random = ~ year | id, family = binomial())
fm3 <- mixed_model(ascites ~ year + age, data = pbc2,
random = ~ year | id, family = binomial())
# [2] Save all the fitted mixed-effects models in a list.
Mixed <- list(fm1, fm2, fm3)
# [3] Fit a Cox model, specifying the baseline covariates to be included in the
# joint model.
fCox1 <- coxph(Surv(years, status2) ~ drug + age, data = pbc2.id)
# [4] The joint model is fitted using a call to jm() i.e.,
joint_model_fit_2 <- jm(fCox1, Mixed, time_var = "year",
n_chains = 1L, n_iter = 11000L, n_burnin = 1000L)
summary(joint_model_fit_2)
#>
#> Call:
#> JMbayes2::jm(Surv_object = fCox1, Mixed_objects = Mixed, time_var = "year",
#> n_chains = 1L, n_iter = 11000L, n_burnin = 1000L)
#>
#> Data Descriptives:
#> Number of Groups: 312 Number of events: 140 (44.9%)
#> Number of Observations:
#> log(serBilir): 1945
#> hepatomegaly: 1884
#> ascites: 1885
#>
#> DIC WAIC LPML
#> marginal 6642.124 6855.619 -3657.905
#> conditional 9083.033 8826.991 -4889.348
#>
#> Random-effects covariance matrix:
#>
#> StdDev Corr
#> (Intr) 0.9912 (Intr) year (Intr) year (Intr)
#> year 0.1757 0.3802
#> (Intr) 3.2808 0.5267 0.3405
#> year 0.5670 0.0444 0.3482 -0.3466
#> (Intr) 2.8763 0.6201 0.4974 0.5264 -0.0074
#> year 0.4205 0.3543 0.6047 0.3516 0.2719 -0.0672
#>
#> Survival Outcome:
#> Mean StDev 2.5% 97.5% P
#> drugD-penicil -0.1890 0.2679 -0.7106 0.3437 0.4658
#> age 0.0330 0.0143 0.0032 0.0584 0.0316
#> value(log(serBilir)) 0.7016 0.2205 0.2706 1.1292 0.0084
#> value(hepatomegaly) -0.0515 0.0829 -0.2015 0.1152 0.5190
#> value(ascites) 0.5672 0.2027 0.2048 1.0108 0.0000
#>
#> Longitudinal Outcome: log(serBilir) (family = gaussian, link = identity)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) 0.6726 0.1405 0.3984 0.9542 0.0000
#> year 0.2465 0.0276 0.1933 0.3007 0.0000
#> sexfemale -0.2054 0.1446 -0.4946 0.0722 0.1492
#> year:sexfemale -0.0649 0.0283 -0.1209 -0.0106 0.0186
#> sigma 0.3479 0.0068 0.3351 0.3620 0.0000
#>
#> Longitudinal Outcome: hepatomegaly (family = binomial, link = logit)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) 0.0769 1.0083 -1.8713 2.0778 0.9420
#> sexfemale -0.7586 0.5246 -1.8069 0.2517 0.1386
#> age 0.0146 0.0162 -0.0175 0.0466 0.3664
#> year 0.2461 0.0689 0.1083 0.3800 0.0000
#>
#> Longitudinal Outcome: ascites (family = binomial, link = logit)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) -9.0119 1.0153 -11.1983 -7.1497 0
#> year 0.5763 0.0687 0.4611 0.7208 0
#> age 0.0811 0.0160 0.0507 0.1152 0
#>
#> MCMC summary:
#> chains: 1
#> iterations per chain: 11000
#> burn-in per chain: 1000
#> thinning: 1
#> time: 1.3 min
traceplot(joint_model_fit_2)
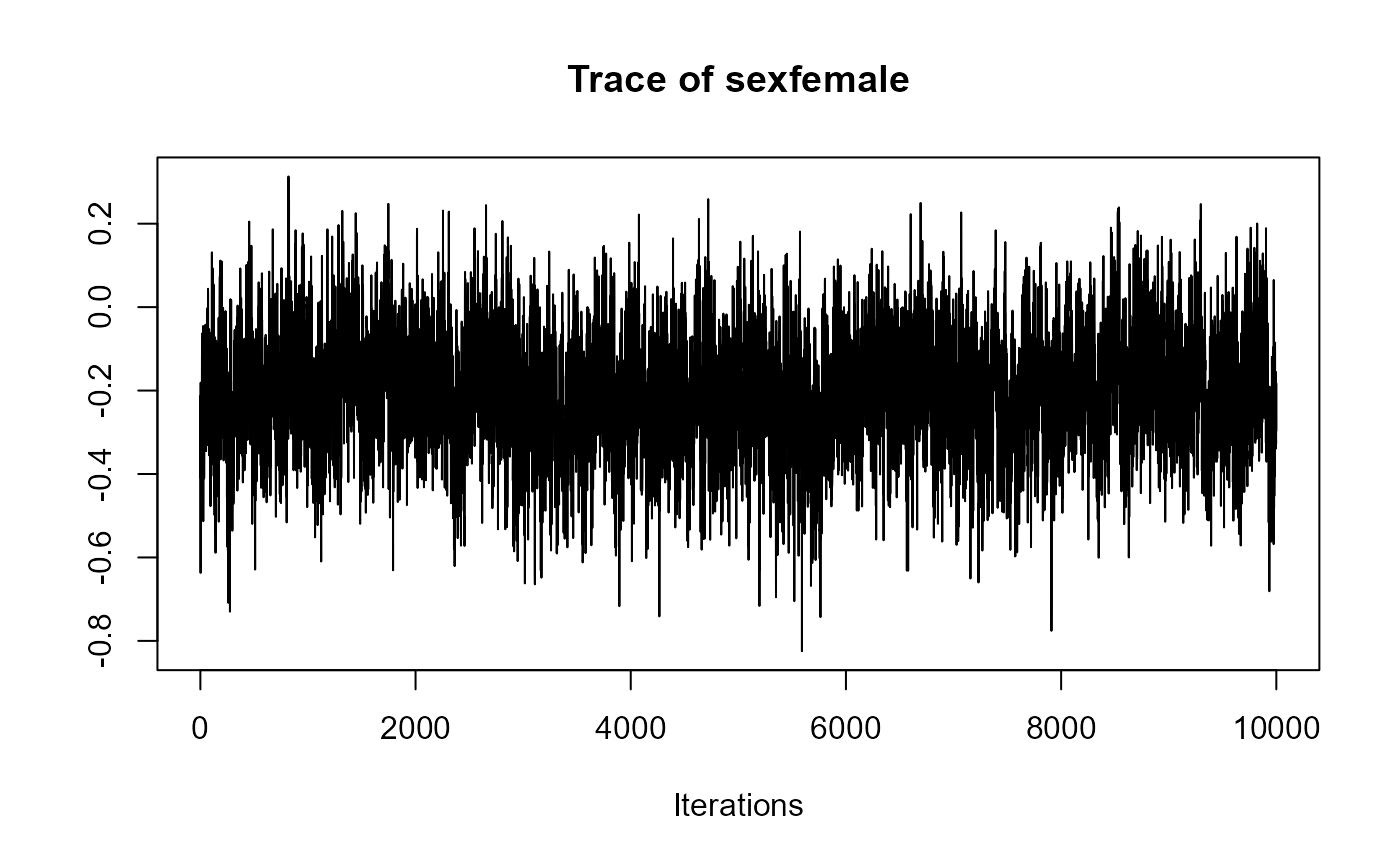
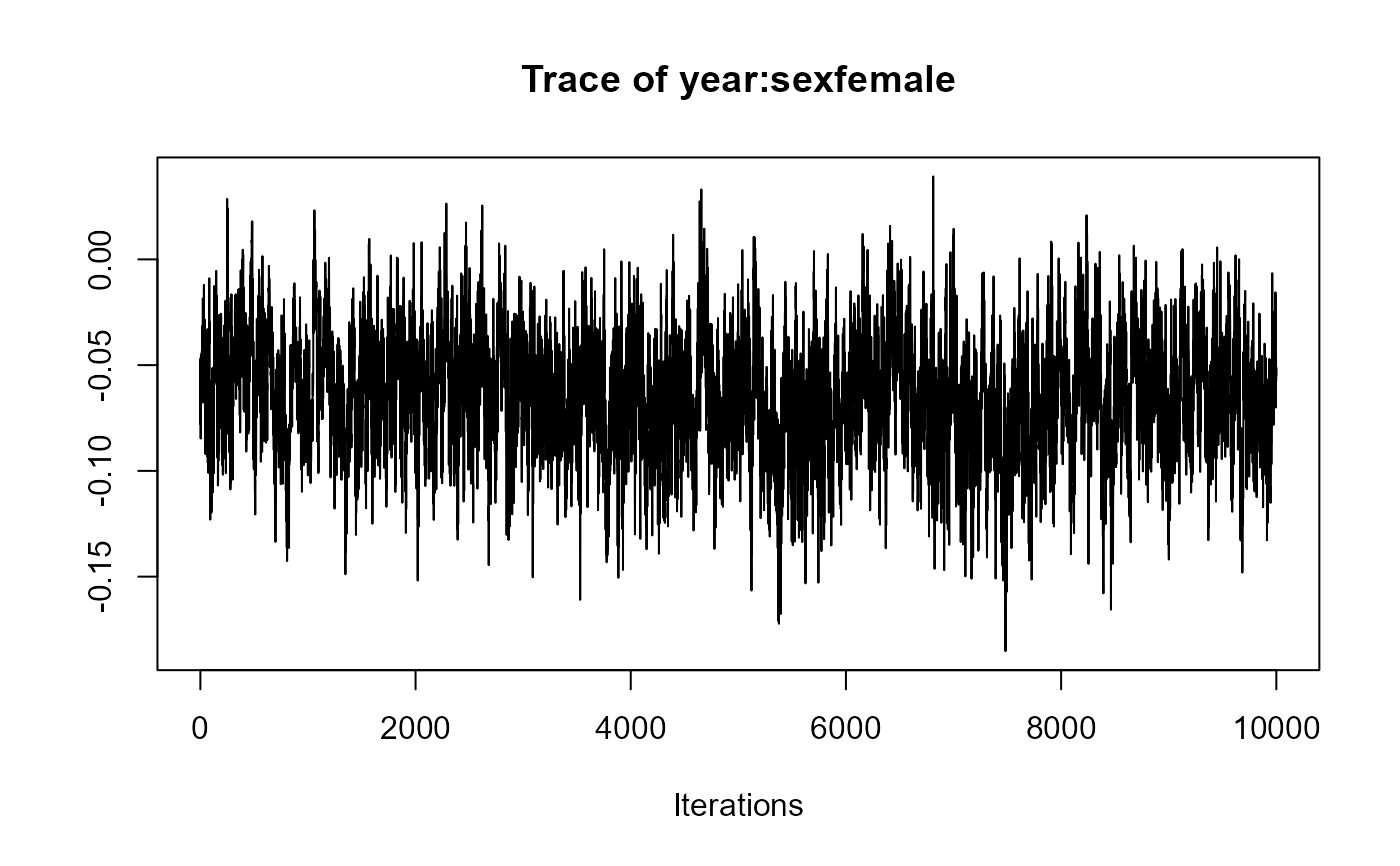
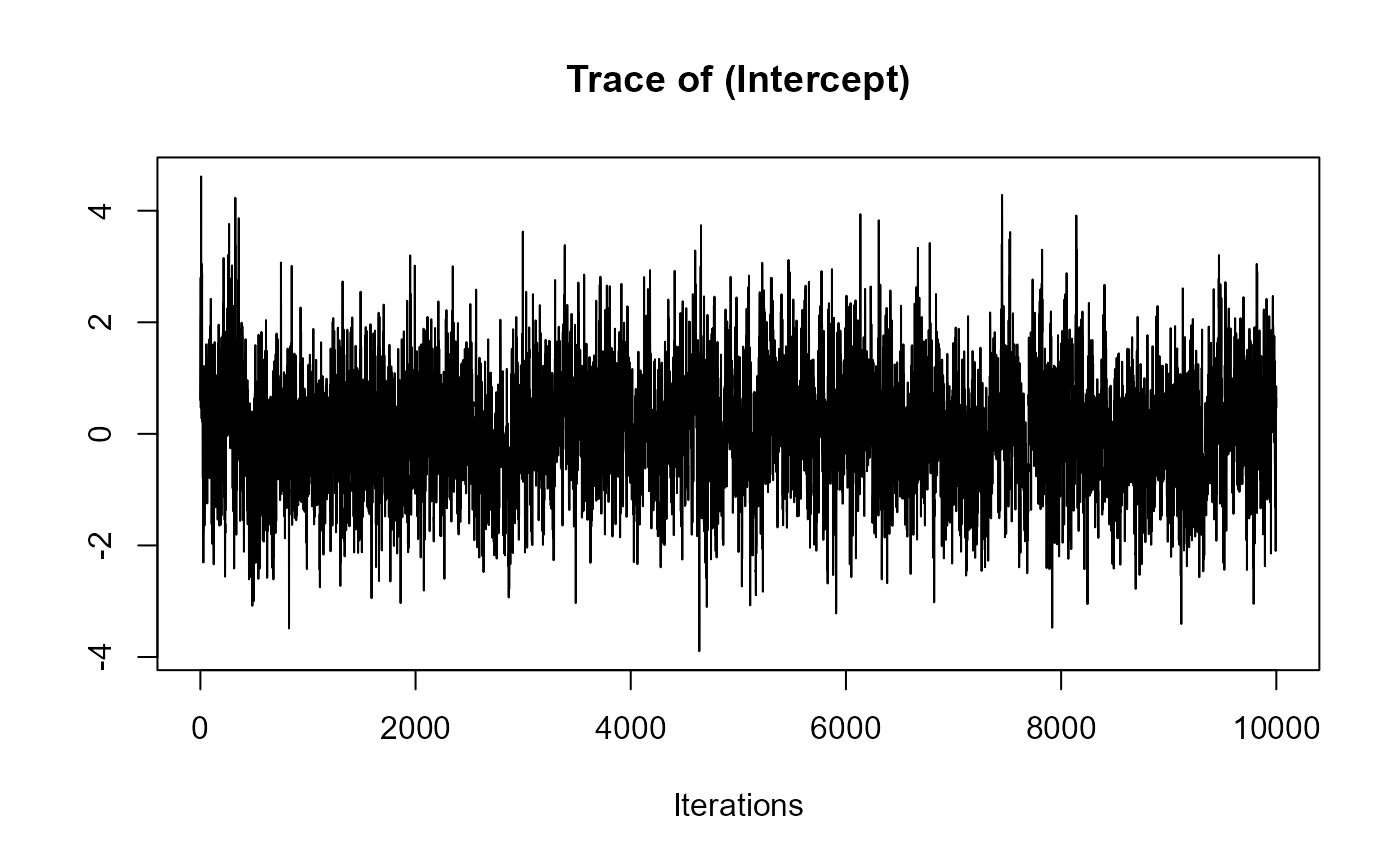
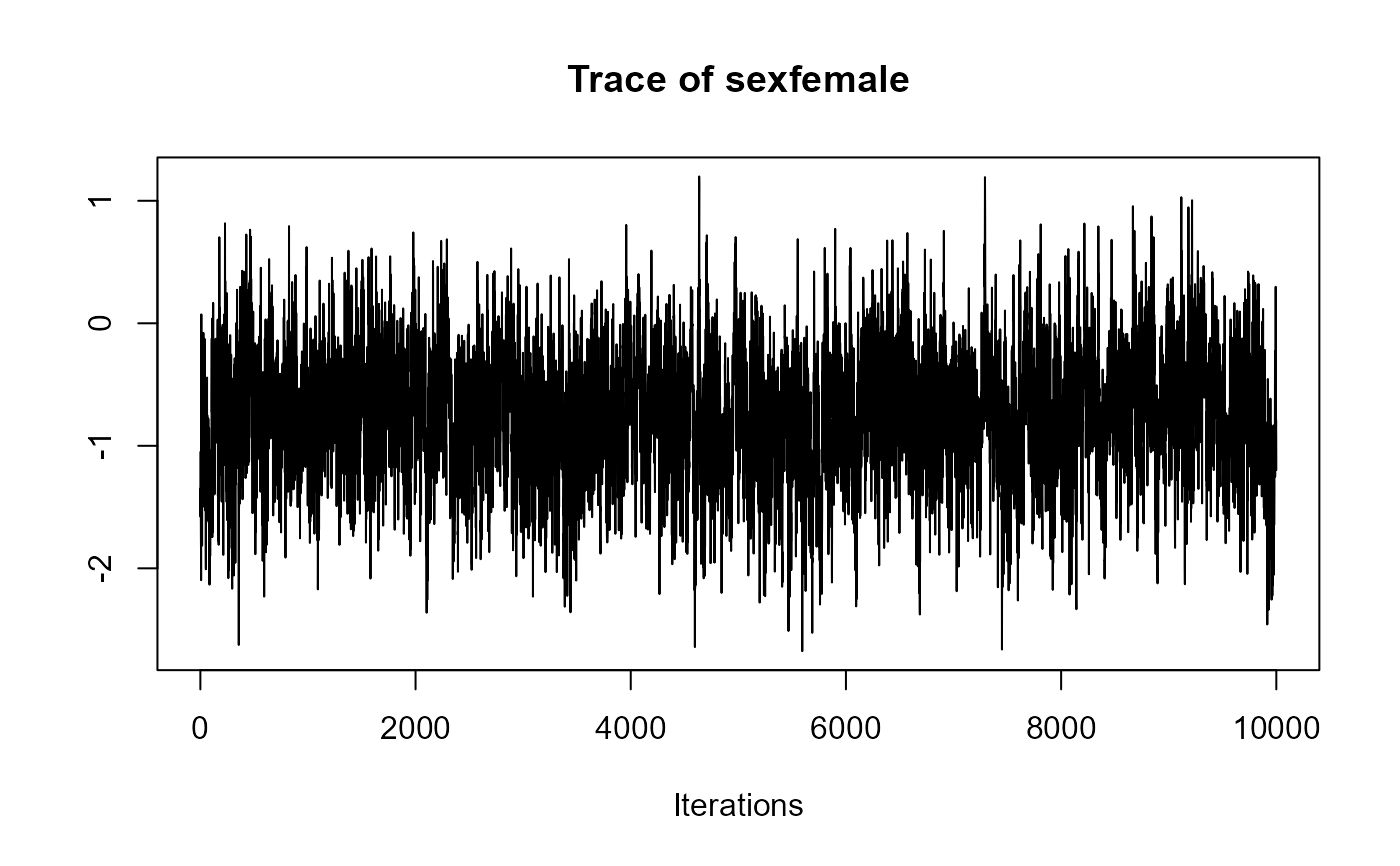
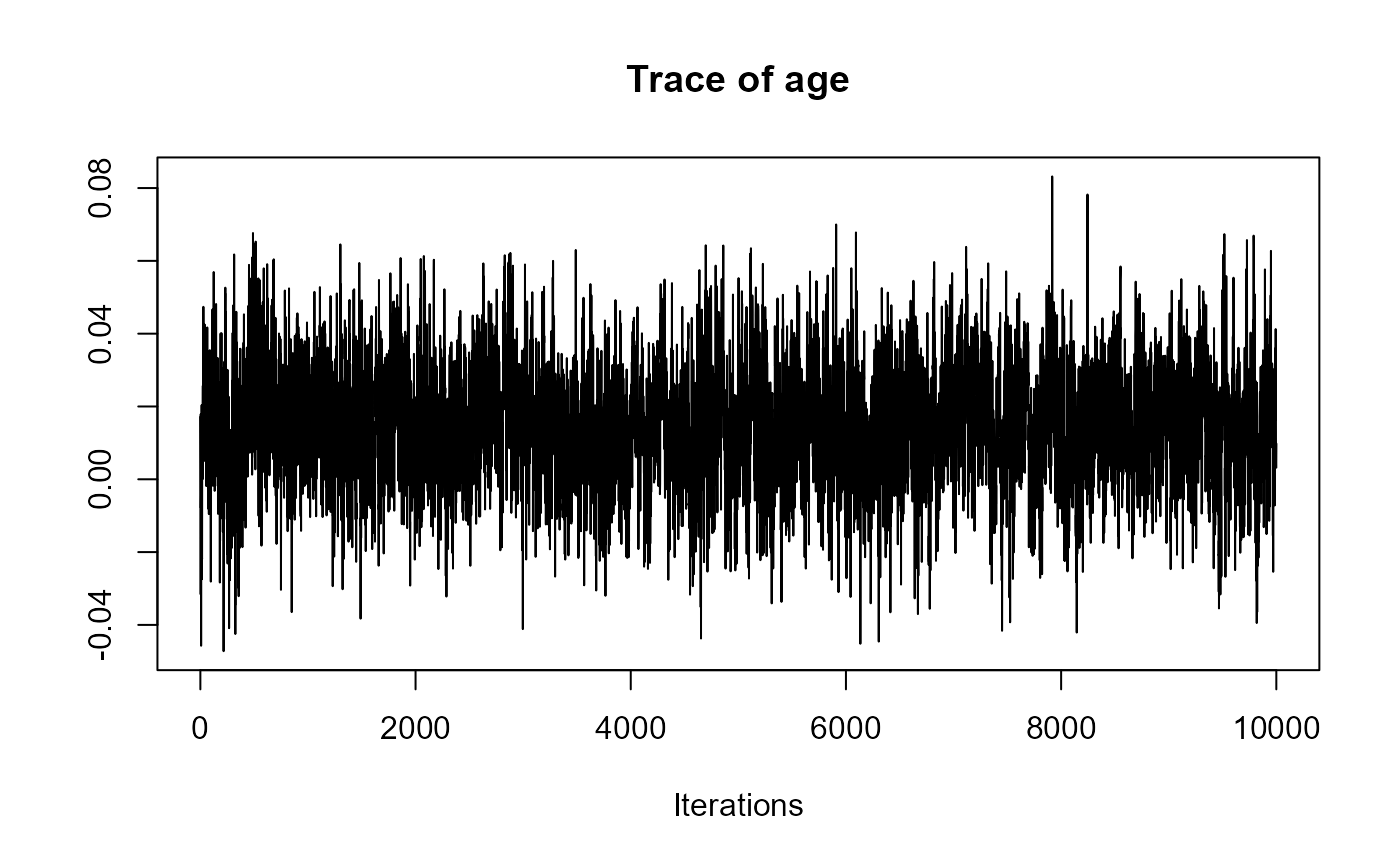
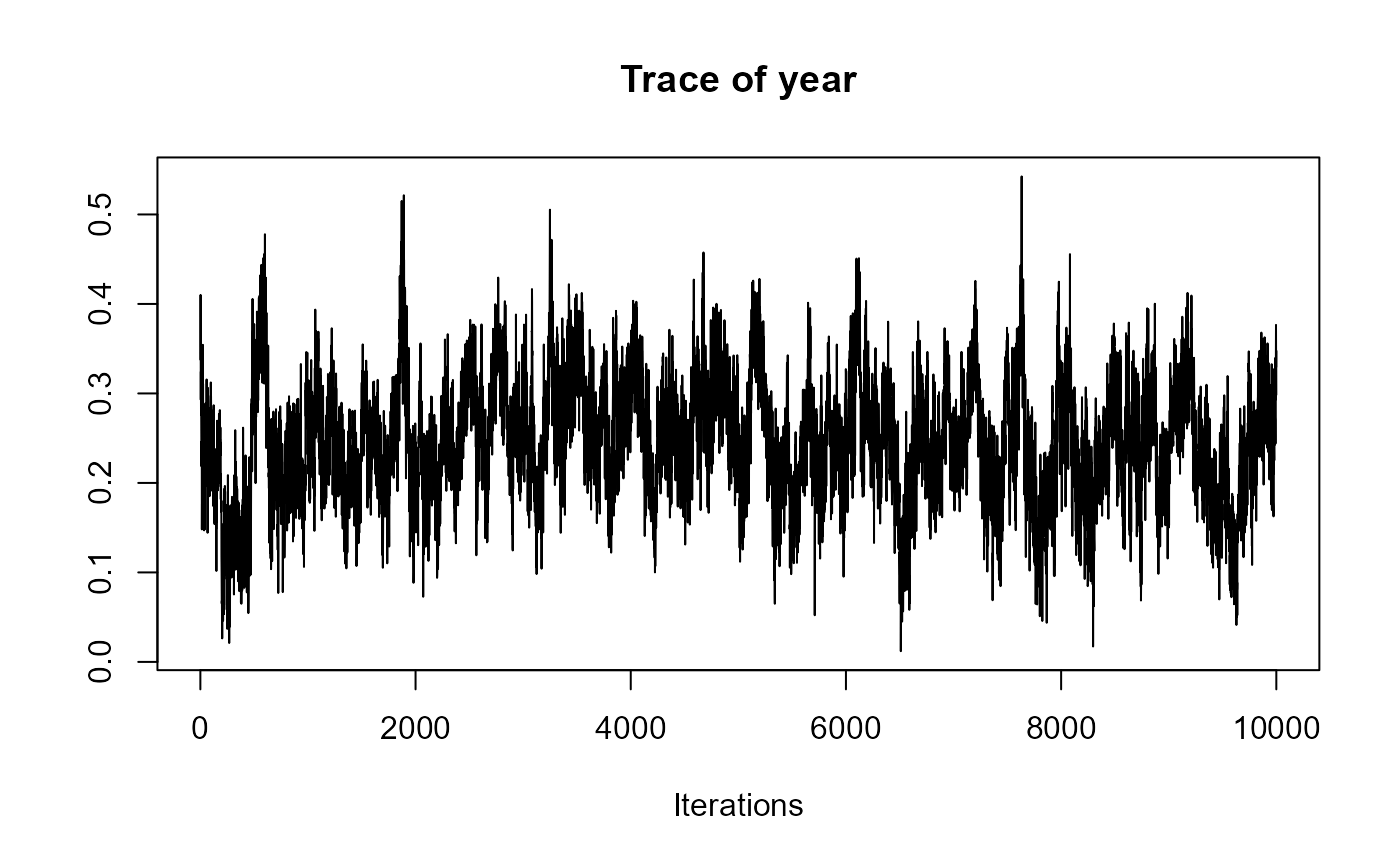
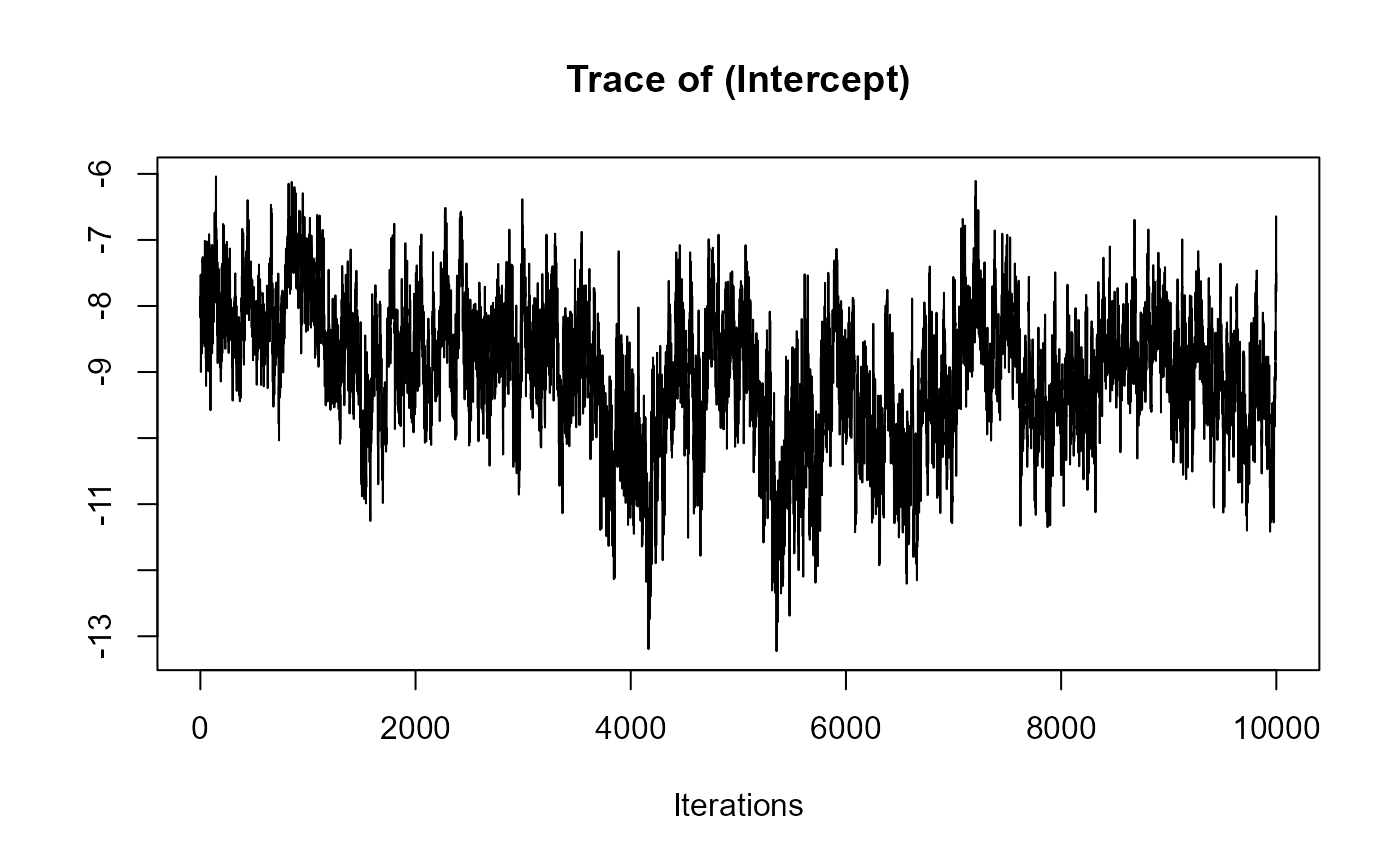
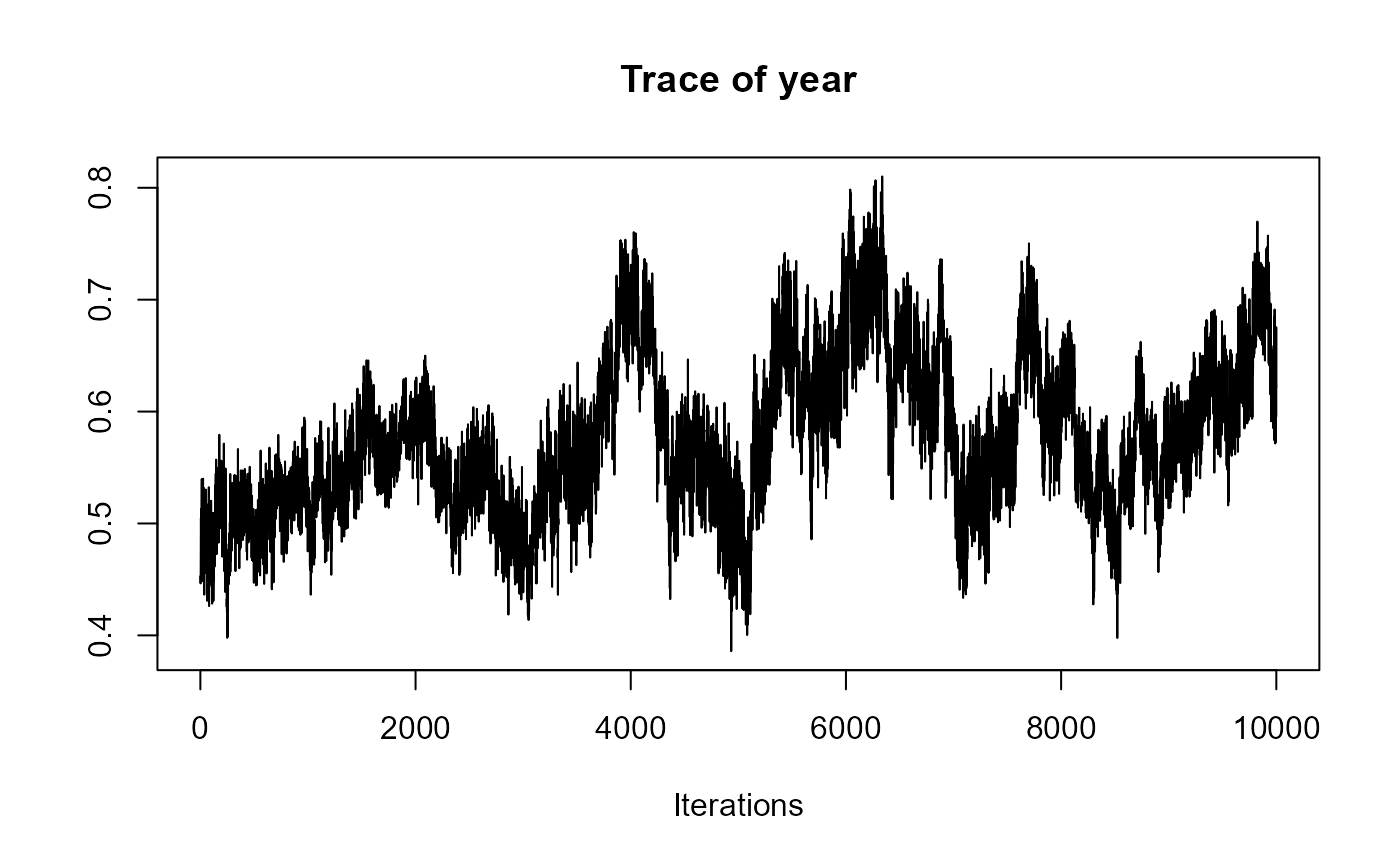
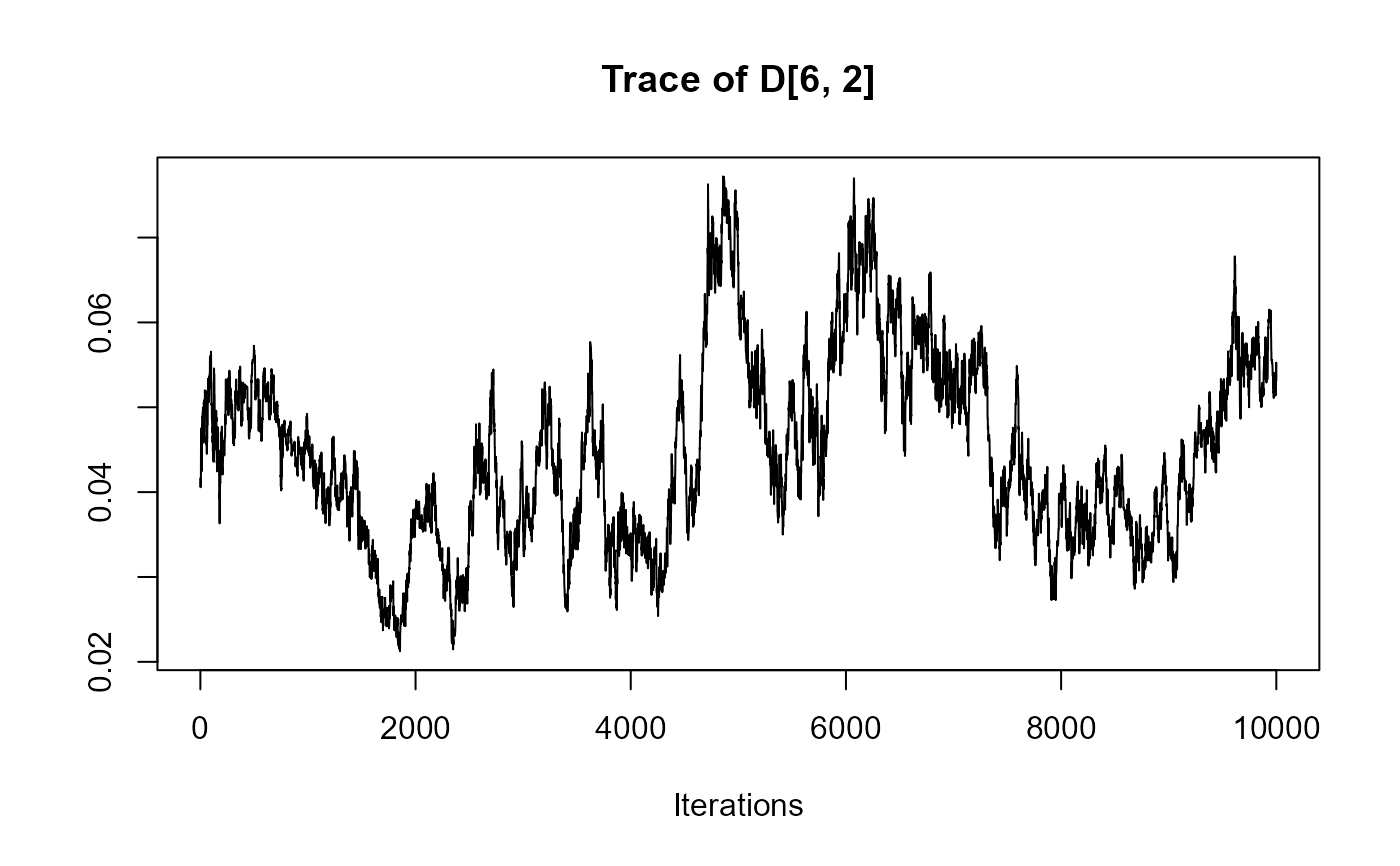
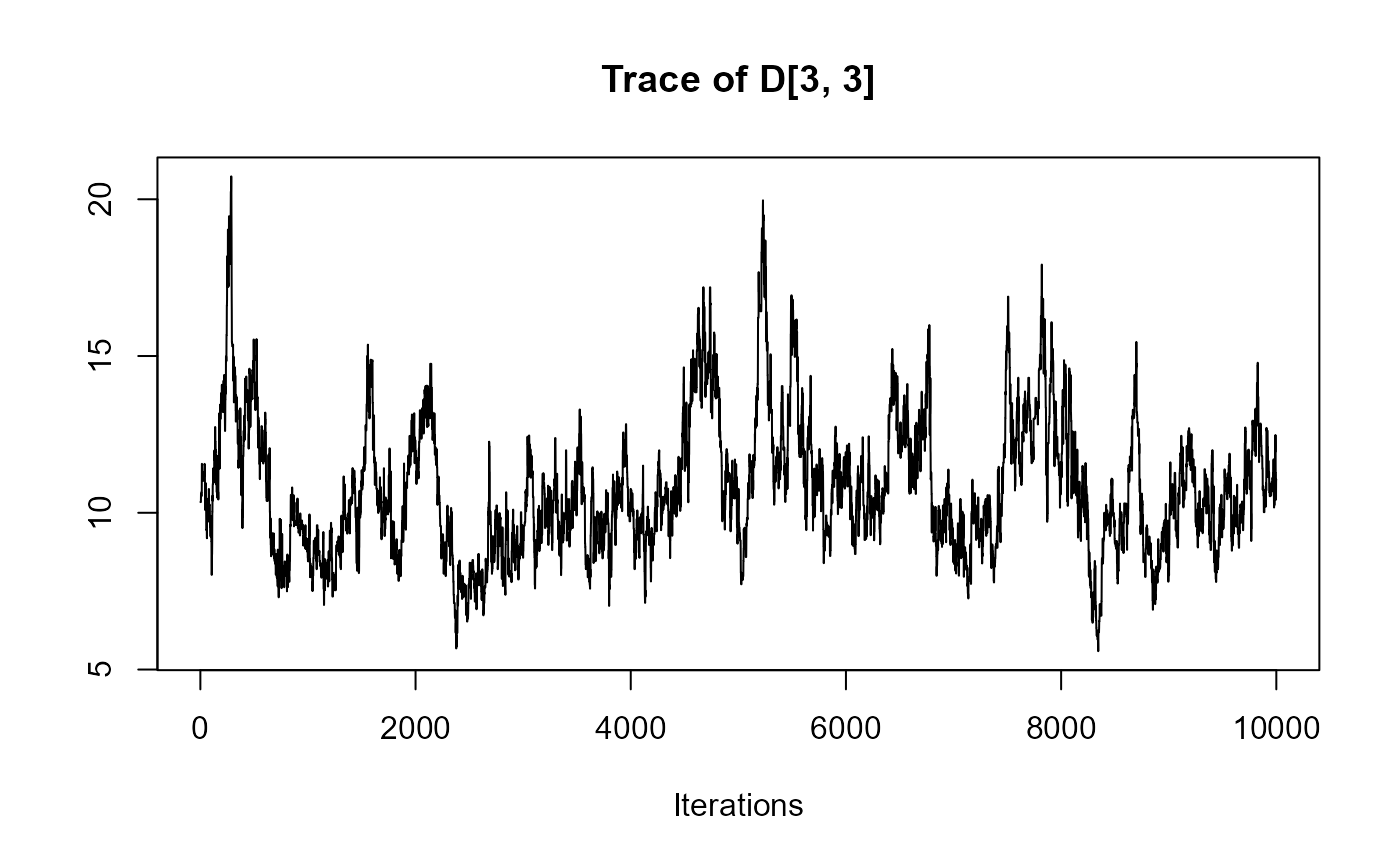
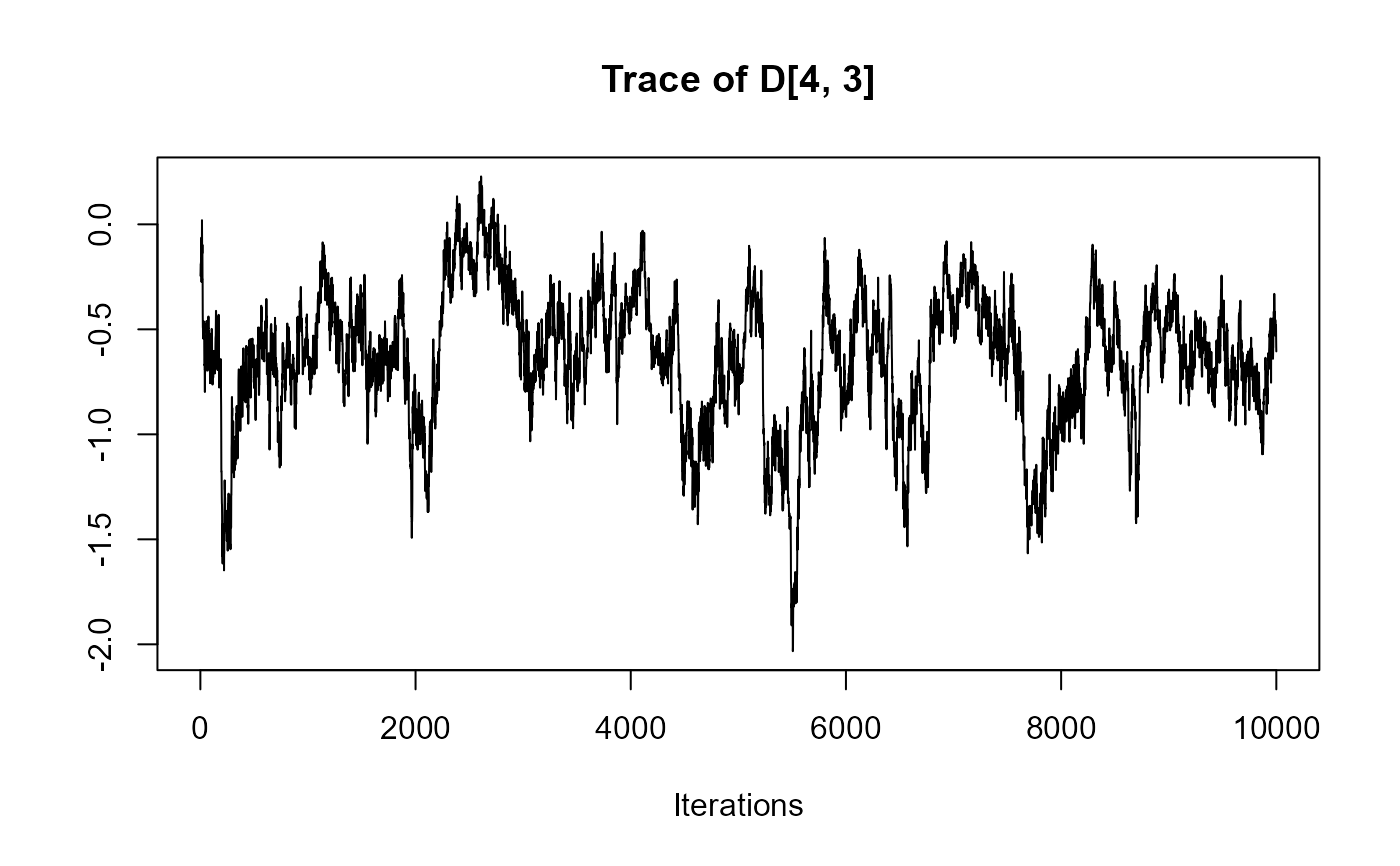
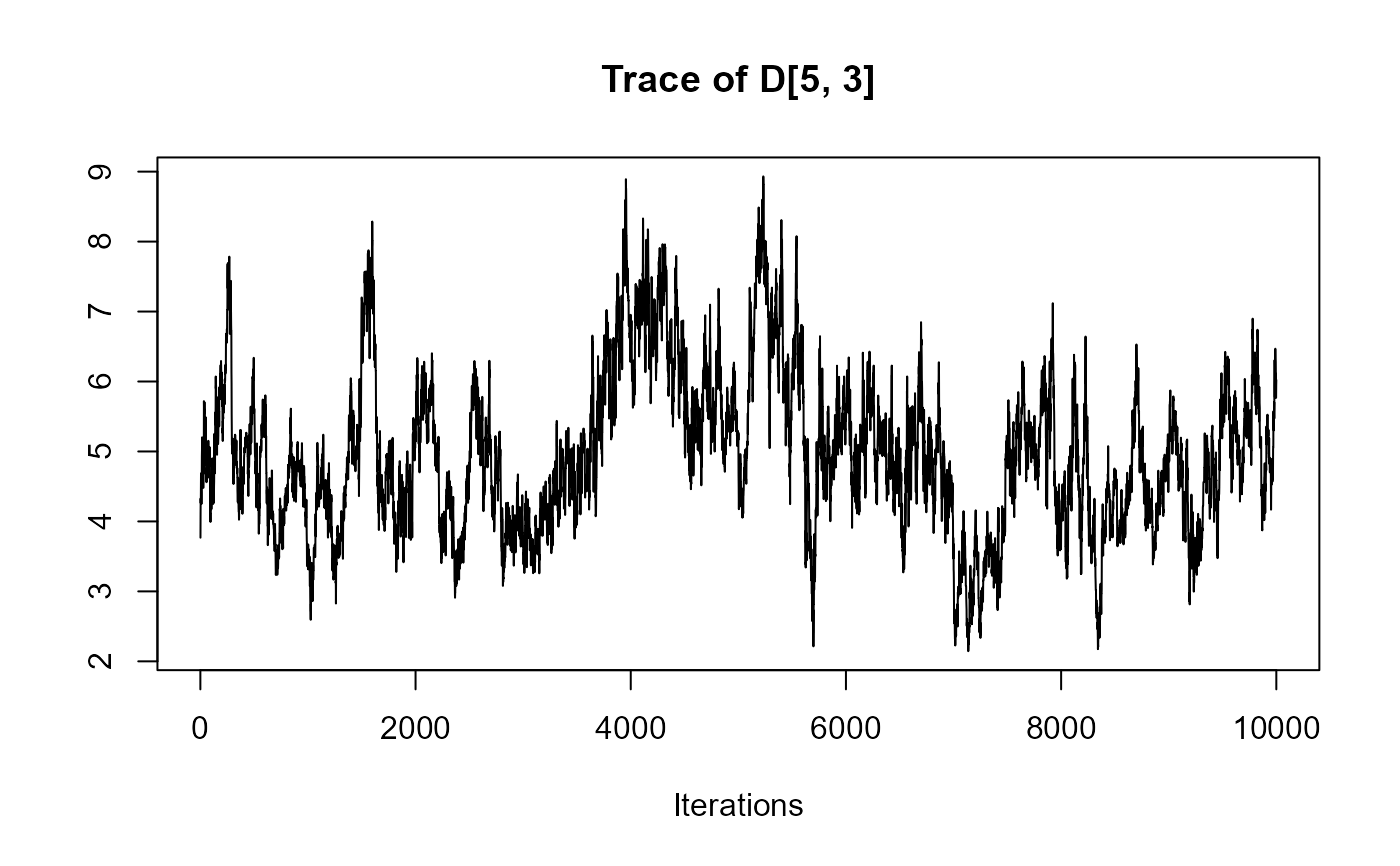
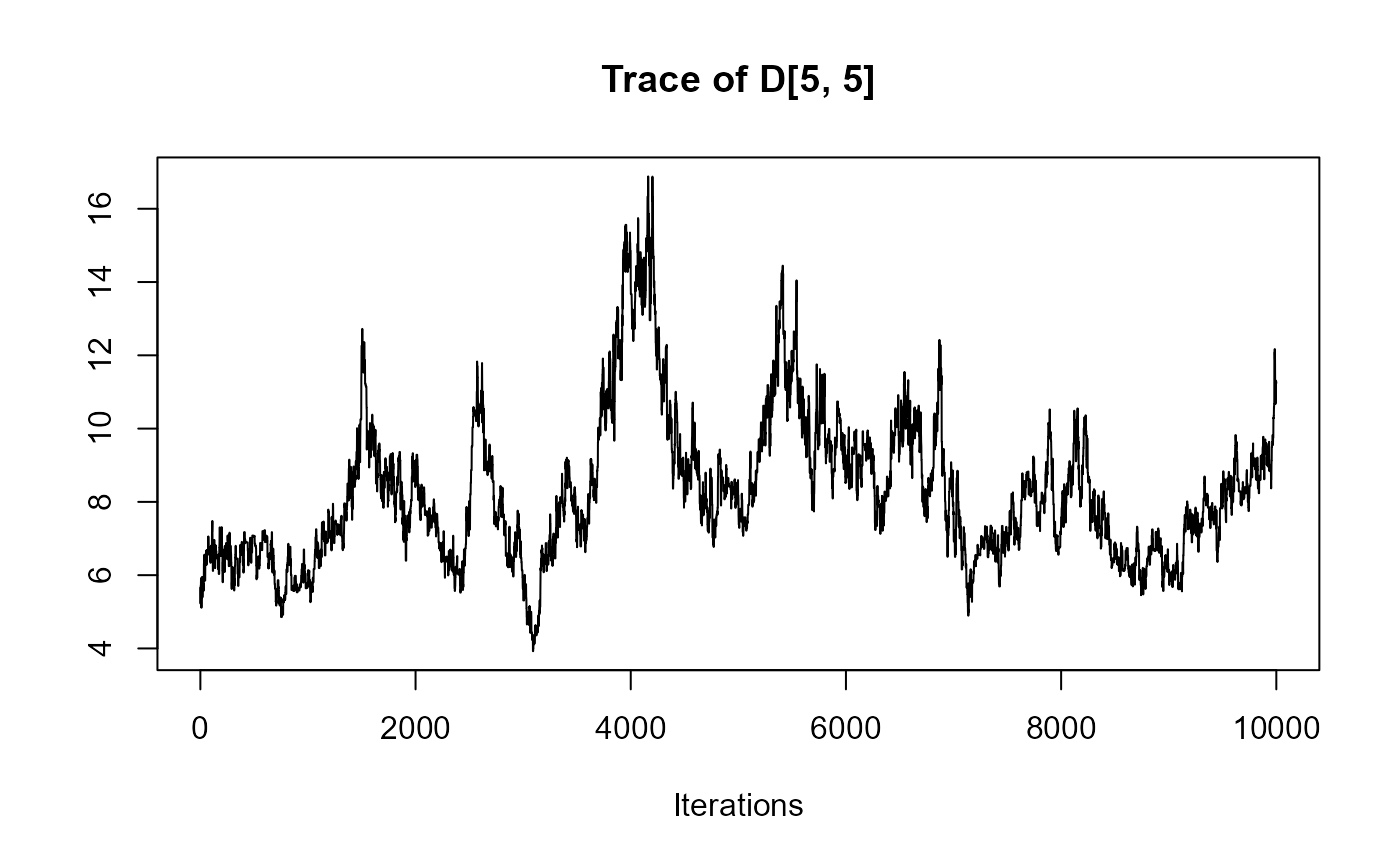
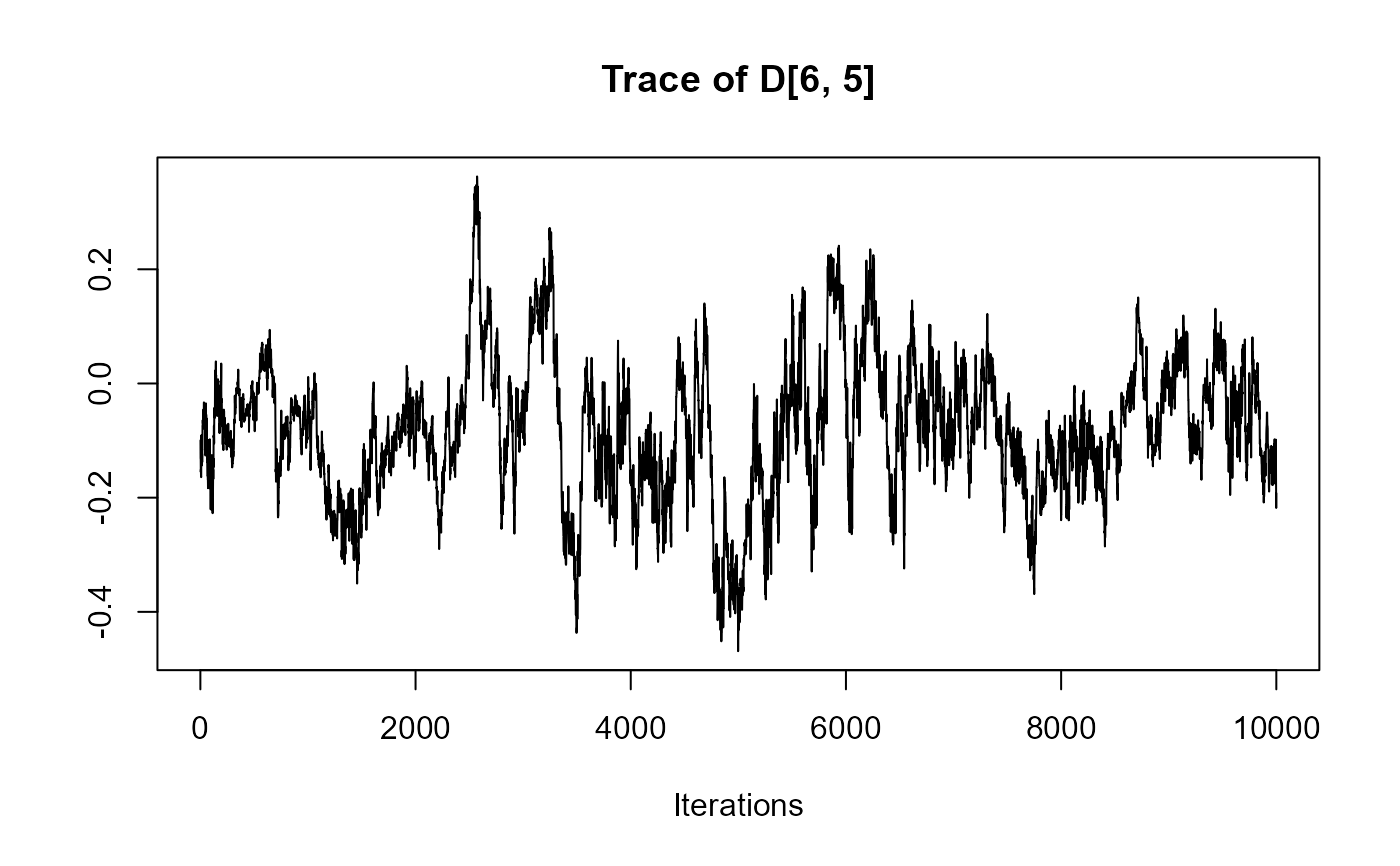
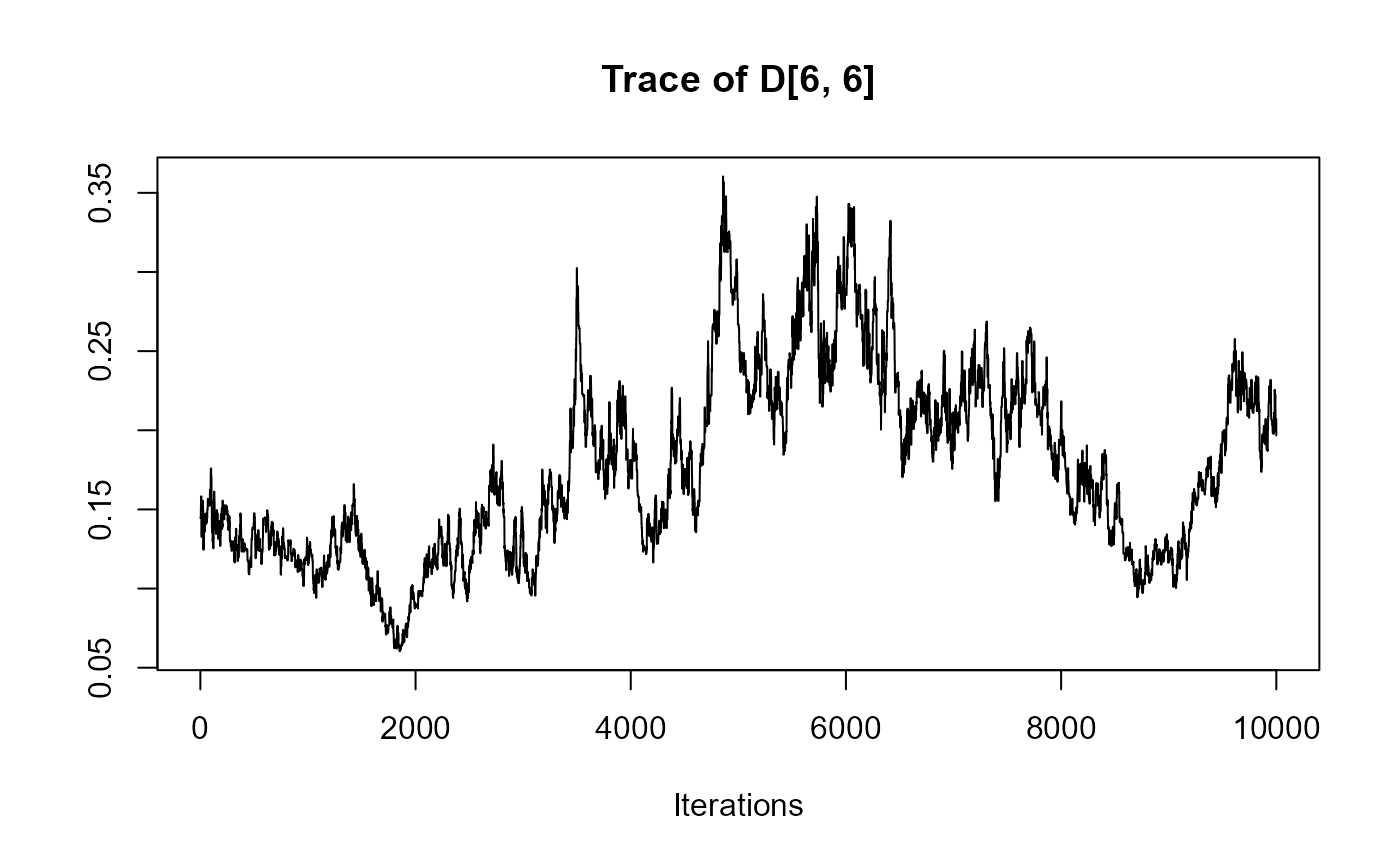
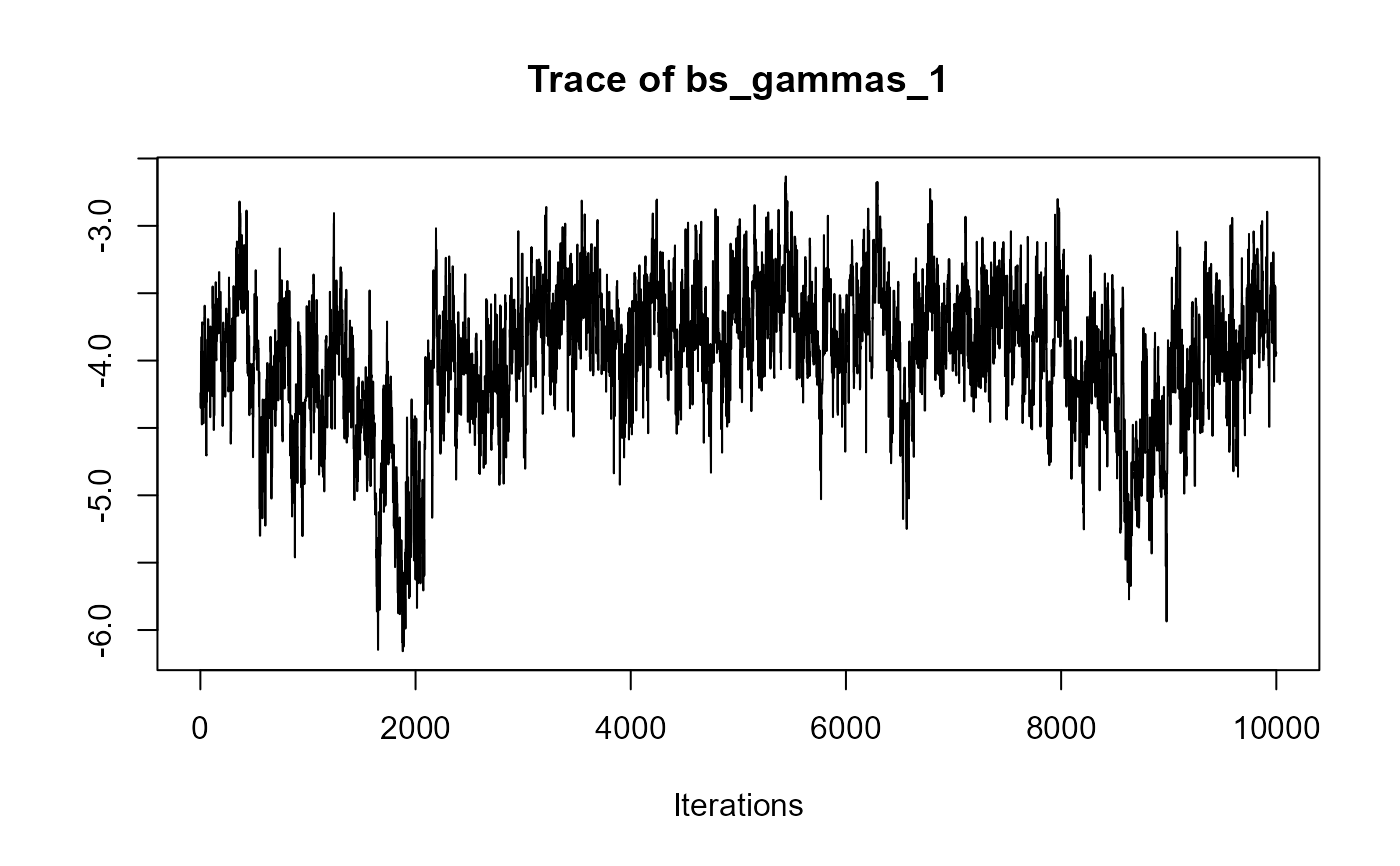
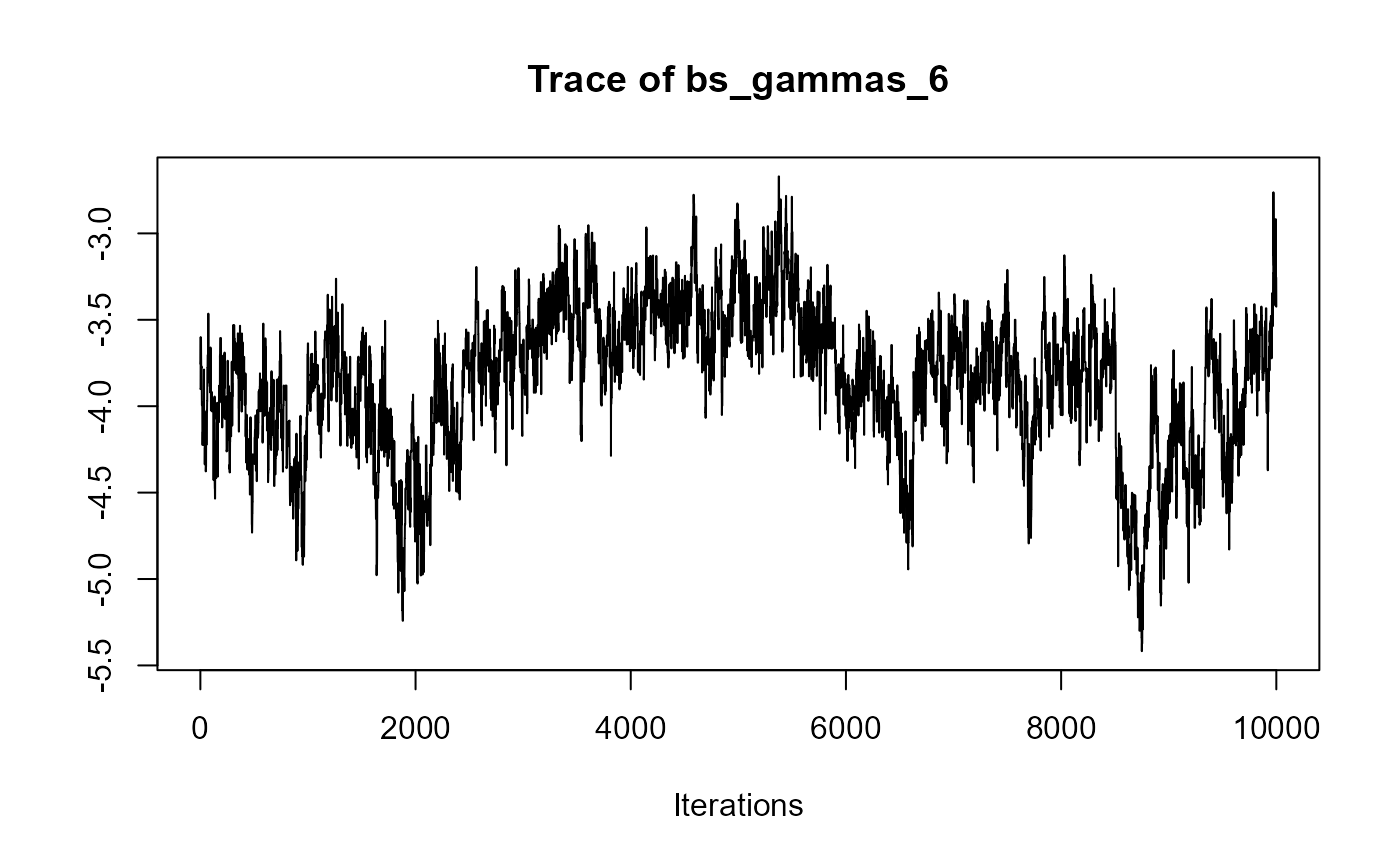
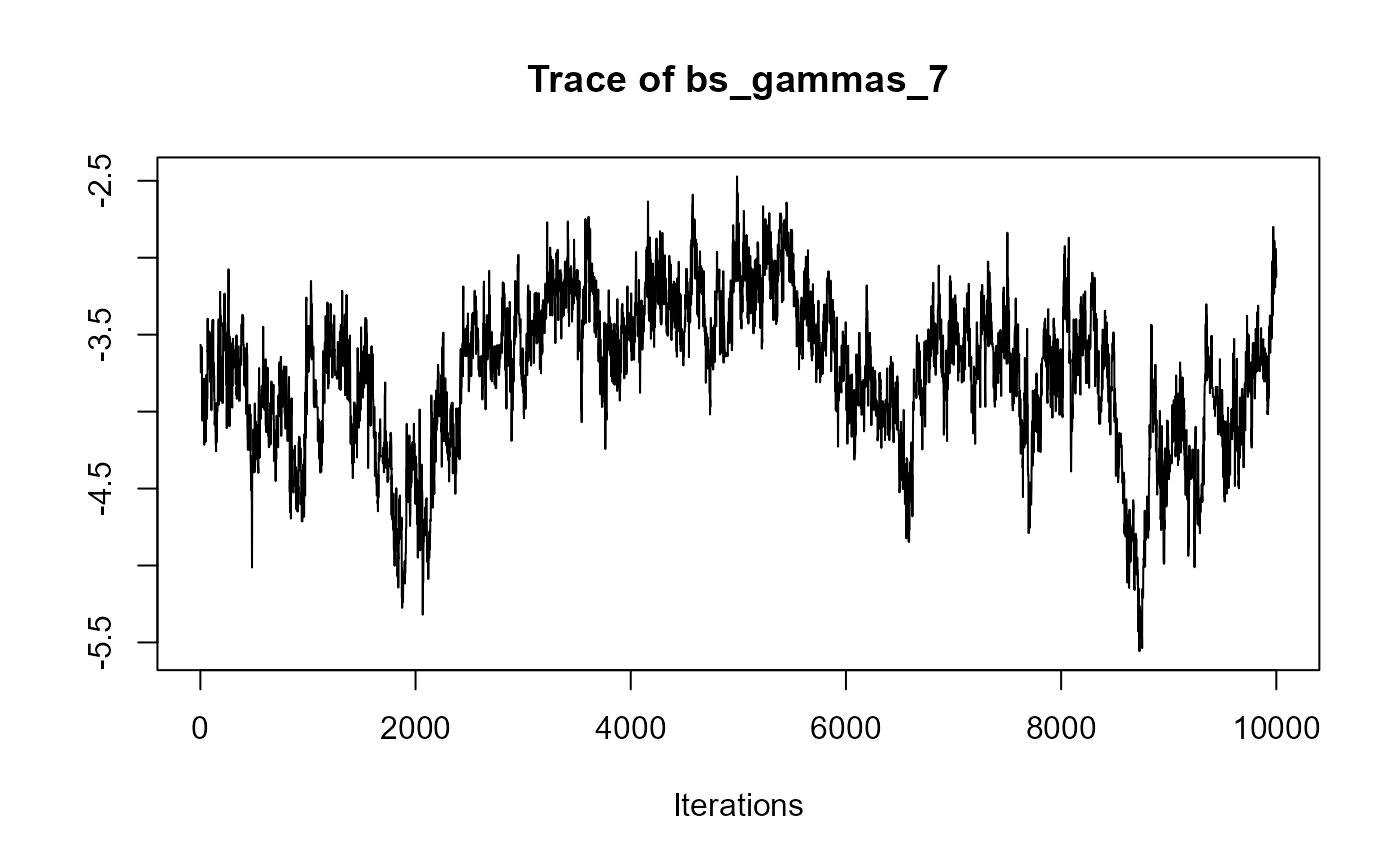
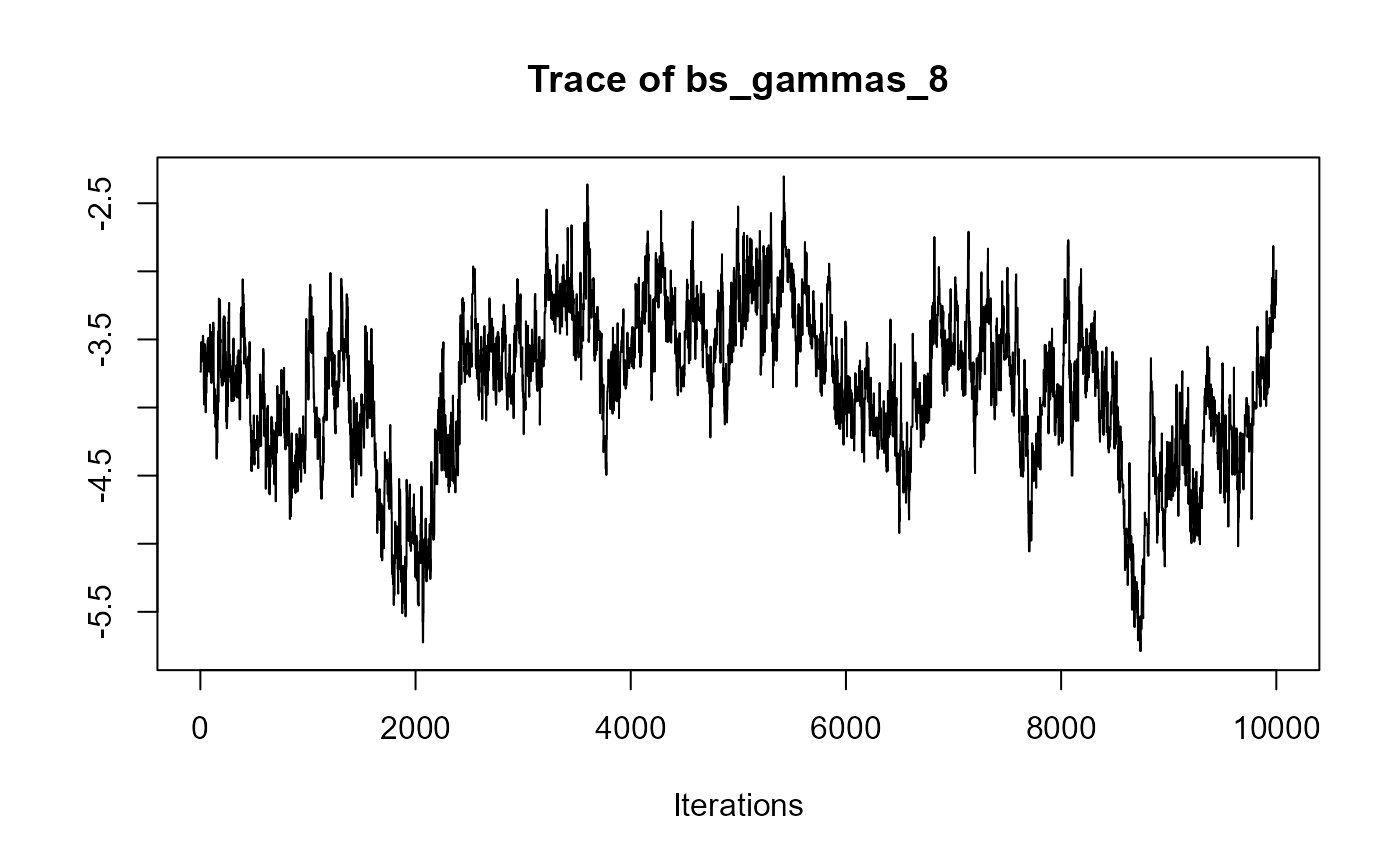
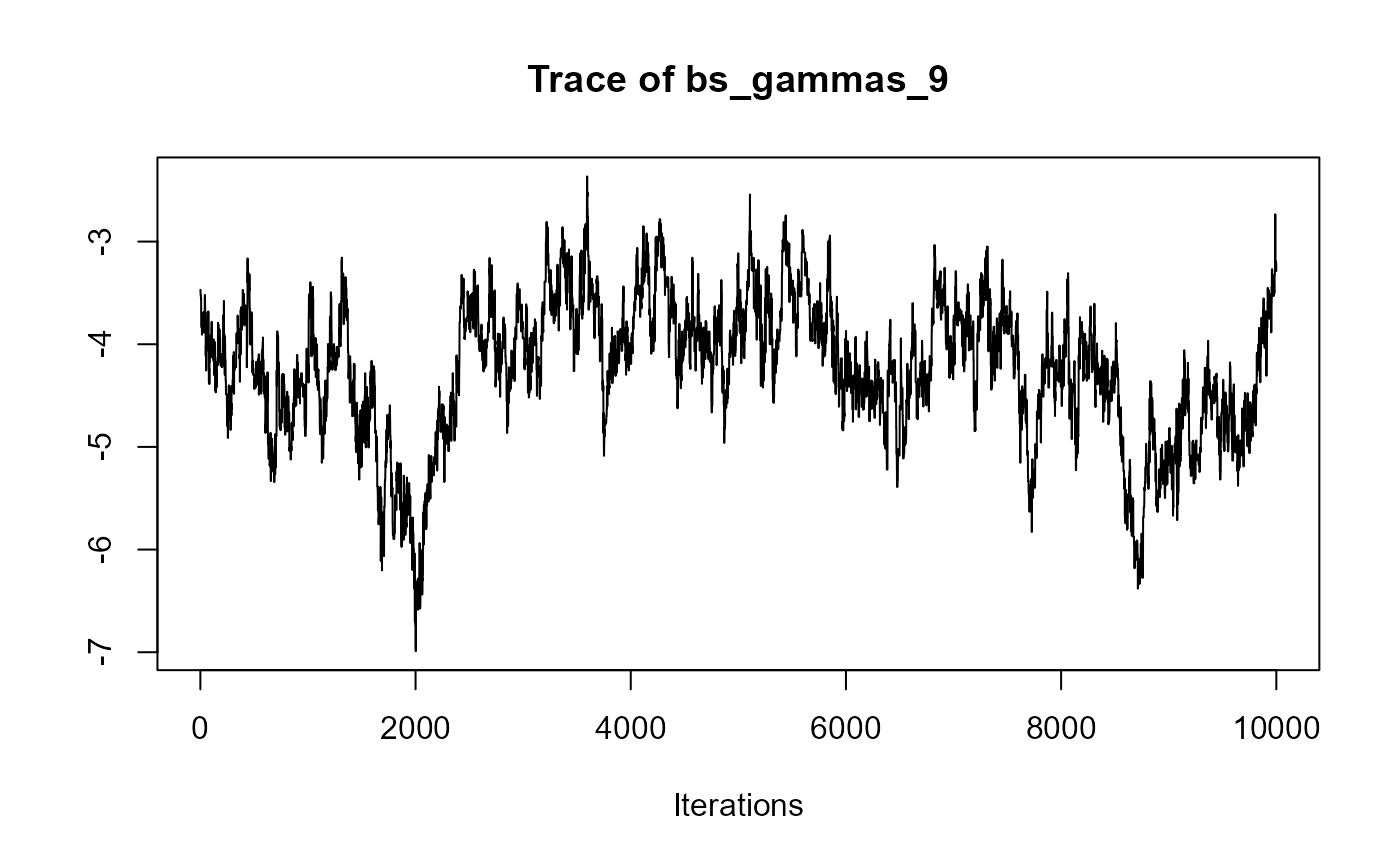
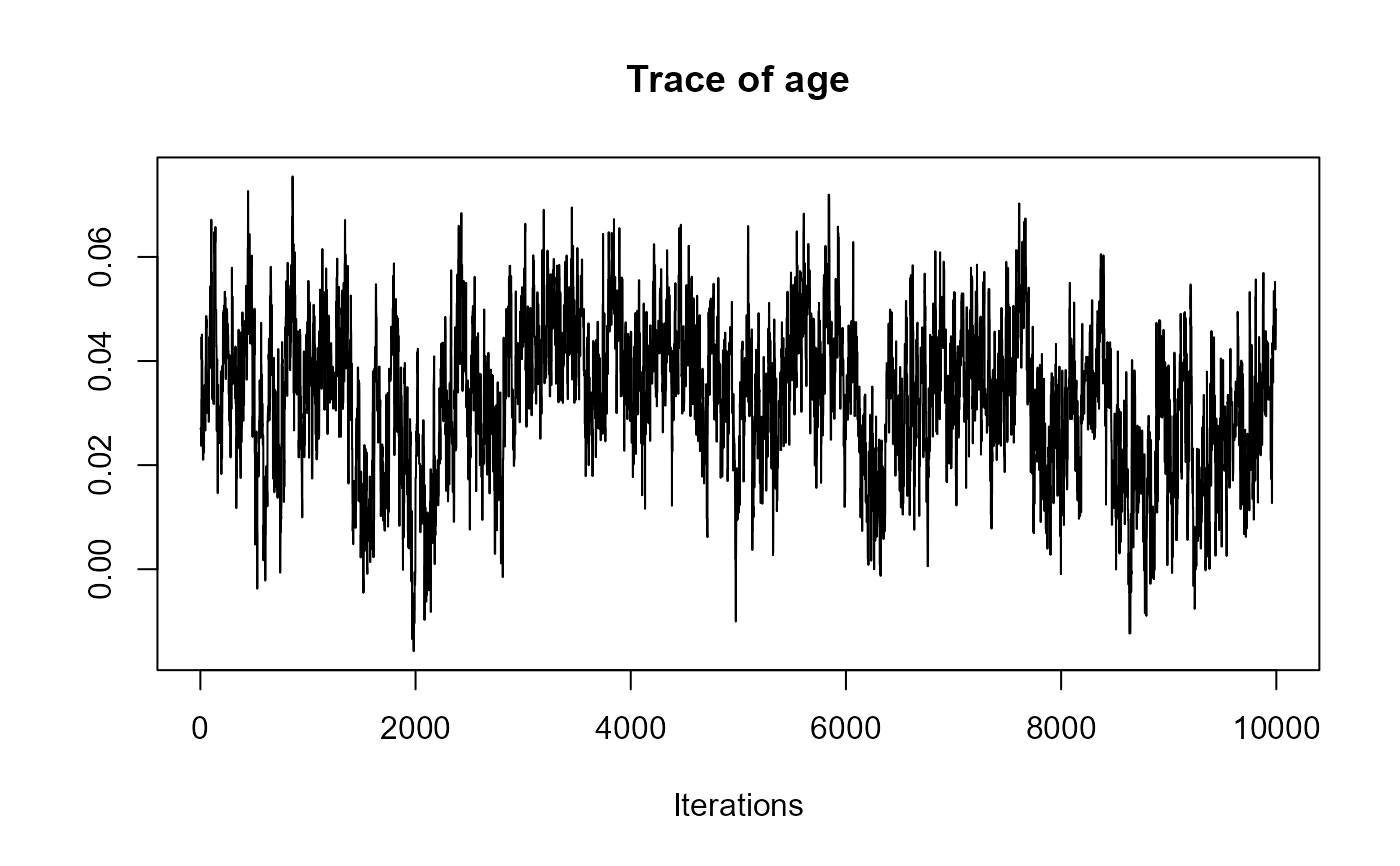
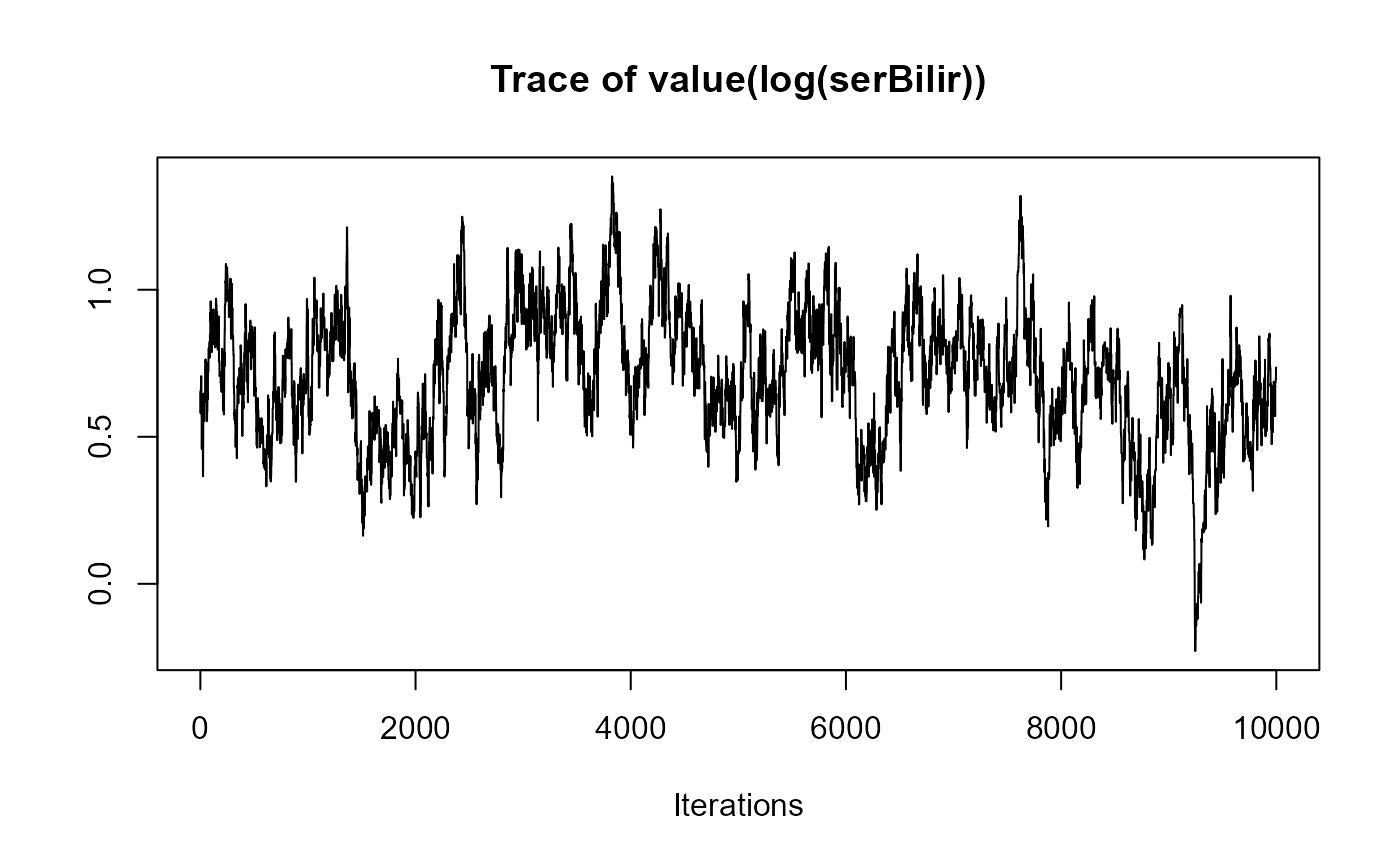
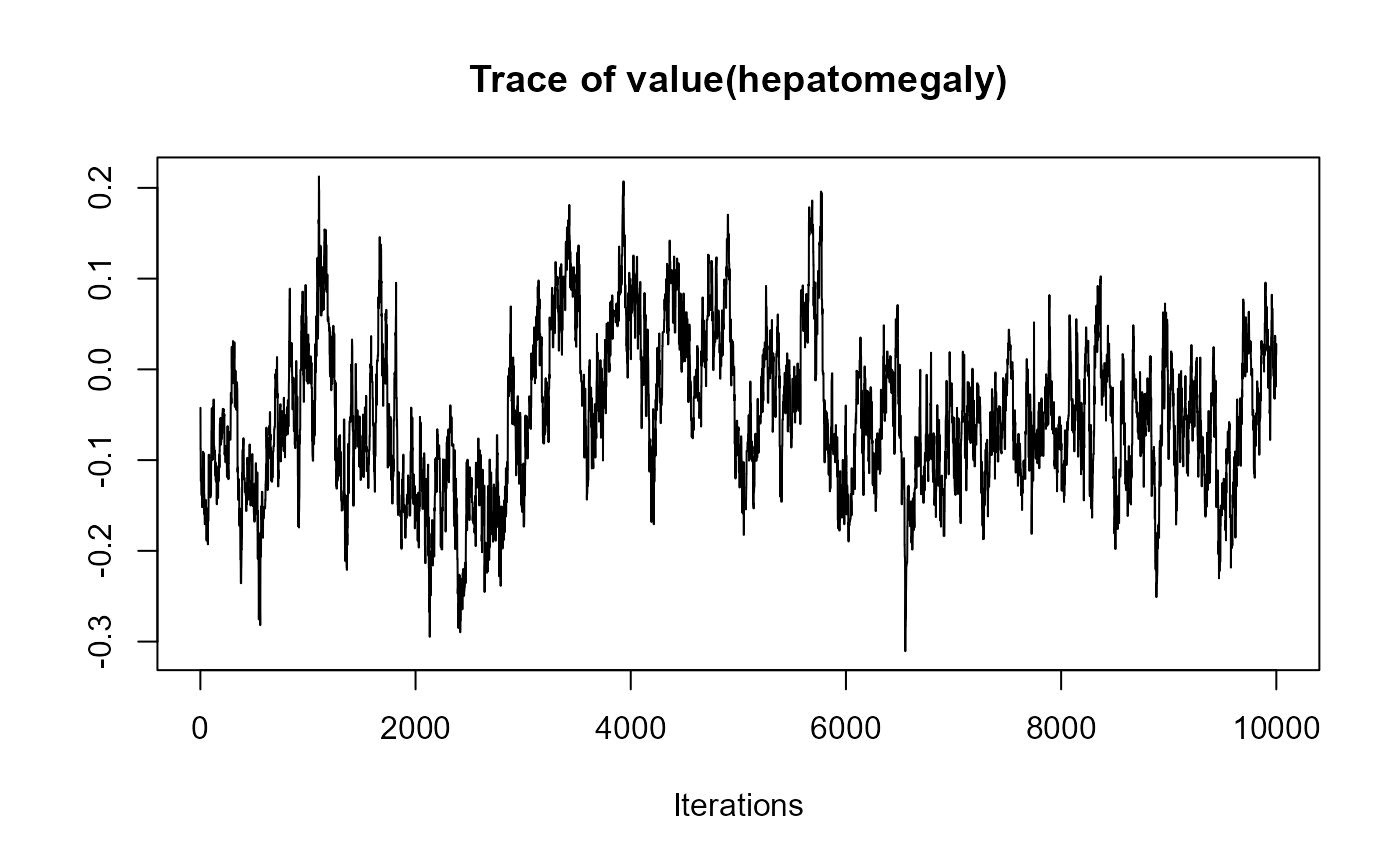
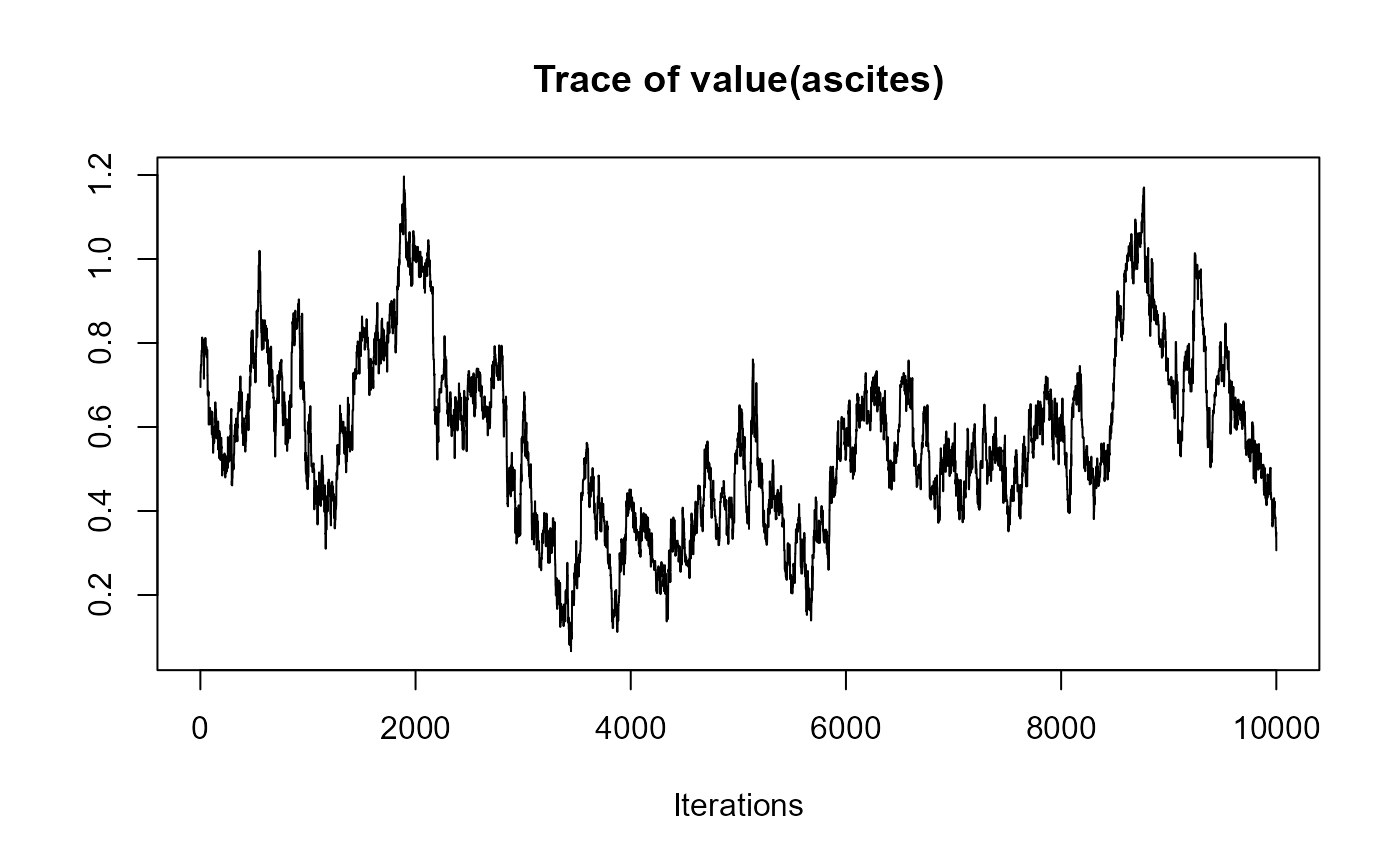 ################################################################################
######################
# Slope & Area Terms #
######################
# We extend model 'joint_model_fit_2' by including the value and slope term for
# bilirubin, the area term for hepatomegaly (in the log-odds scale), and the
# value and area term for spiders (in the log-odds scale).
# To include these terms into the model, we specify the 'functional_forms'
# argument. This should be a list of right side formulas. Each component of the
# list should have as name the name of the corresponding outcome variable. In
# the right side formula we specify the functional form of the association using
# functions 'value()', 'slope()' and 'area()'.
# Notes: (1) For terms not specified in the 'functional_forms' list, the default
# value functional form is used.
# [1] Fit the mixed-effects models using lme() for continuous outcomes
# and mixed_model() for categorical outcomes.
fm1 <- lme(fixed = log(serBilir) ~ year * sex, random = ~ year | id, data = pbc2)
fm2 <- mixed_model(hepatomegaly ~ sex + age + year, data = pbc2,
random = ~ year | id, family = binomial())
fm3 <- mixed_model(ascites ~ year + age, data = pbc2,
random = ~ year | id, family = binomial())
# [2] Save all the fitted mixed-effects models in a list.
Mixed <- list(fm1, fm2, fm3)
# [3] Fit a Cox model, specifying the baseline covariates to be included in the
# joint model.
fCox1 <- coxph(Surv(years, status2) ~ drug + age, data = pbc2.id)
# [4] Specify the list of formulas to be passed to the functional_forms argument
# of jm().
fForms <- list("log(serBilir)" = ~ value(log(serBilir)) + slope(log(serBilir)),
"hepatomegaly" = ~ area(hepatomegaly),
"ascites" = ~ value(ascites) + area(ascites))
# [5] The joint model is fitted using a call to jm() and passing the list
# to the functional_forms argument.
joint_model_fit_2 <- jm(fCox1, Mixed, time_var = "year",
functional_forms = fForms, n_chains = 1L,
n_iter = 11000L, n_burnin = 1000L)
summary(joint_model_fit_2)
#>
#> Call:
#> JMbayes2::jm(Surv_object = fCox1, Mixed_objects = Mixed, time_var = "year",
#> functional_forms = fForms, n_chains = 1L, n_iter = 11000L,
#> n_burnin = 1000L)
#>
#> Data Descriptives:
#> Number of Groups: 312 Number of events: 140 (44.9%)
#> Number of Observations:
#> log(serBilir): 1945
#> hepatomegaly: 1884
#> ascites: 1885
#>
#> DIC WAIC LPML
#> marginal 6643.644 6952.261 -4059.774
#> conditional 8992.791 8720.794 -4830.170
#>
#> Random-effects covariance matrix:
#>
#> StdDev Corr
#> (Intr) 0.9883 (Intr) year (Intr) year (Intr)
#> year 0.1813 0.4185
#> (Intr) 3.3719 0.5278 0.3471
#> year 0.5866 0.0491 0.3639 -0.3638
#> (Intr) 2.2434 0.6558 0.5818 0.6176 -0.1046
#> year 0.3799 0.4802 0.6989 0.4232 0.3547 0.3394
#>
#> Survival Outcome:
#> Mean StDev 2.5% 97.5% P
#> drugD-penicil -0.1146 0.2661 -0.6416 0.3927 0.6798
#> age 0.0484 0.0137 0.0208 0.0754 0.0000
#> value(log(serBilir)) 0.9236 0.2028 0.5630 1.3718 0.0000
#> slope(log(serBilir)) 3.8810 1.3348 1.4004 6.6187 0.0026
#> area(hepatomegaly) 0.1137 0.0836 -0.0660 0.2775 0.1734
#> value(ascites) -0.6728 0.2285 -1.0753 -0.1067 0.0034
#> area(ascites) 1.0142 0.2915 0.1782 1.4328 0.0028
#>
#> Longitudinal Outcome: log(serBilir) (family = gaussian, link = identity)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) 0.7067 0.1429 0.4254 0.9870 0.0000
#> year 0.2605 0.0300 0.2020 0.3203 0.0000
#> sexfemale -0.2451 0.1481 -0.5341 0.0420 0.0988
#> year:sexfemale -0.0716 0.0305 -0.1324 -0.0125 0.0180
#> sigma 0.3483 0.0066 0.3357 0.3618 0.0000
#>
#> Longitudinal Outcome: hepatomegaly (family = binomial, link = logit)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) 0.2790 1.0209 -1.7124 2.2872 0.7926
#> sexfemale -0.9275 0.5312 -1.9833 0.0903 0.0756
#> age 0.0138 0.0165 -0.0190 0.0458 0.3974
#> year 0.2594 0.0730 0.1222 0.4067 0.0004
#>
#> Longitudinal Outcome: ascites (family = binomial, link = logit)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) -8.0466 0.8839 -9.8390 -6.3740 0
#> year 0.4513 0.0598 0.3147 0.5598 0
#> age 0.0733 0.0153 0.0443 0.1052 0
#>
#> MCMC summary:
#> chains: 1
#> iterations per chain: 11000
#> burn-in per chain: 1000
#> thinning: 1
#> time: 1.5 min
# }
################################################################################
######################
# Slope & Area Terms #
######################
# We extend model 'joint_model_fit_2' by including the value and slope term for
# bilirubin, the area term for hepatomegaly (in the log-odds scale), and the
# value and area term for spiders (in the log-odds scale).
# To include these terms into the model, we specify the 'functional_forms'
# argument. This should be a list of right side formulas. Each component of the
# list should have as name the name of the corresponding outcome variable. In
# the right side formula we specify the functional form of the association using
# functions 'value()', 'slope()' and 'area()'.
# Notes: (1) For terms not specified in the 'functional_forms' list, the default
# value functional form is used.
# [1] Fit the mixed-effects models using lme() for continuous outcomes
# and mixed_model() for categorical outcomes.
fm1 <- lme(fixed = log(serBilir) ~ year * sex, random = ~ year | id, data = pbc2)
fm2 <- mixed_model(hepatomegaly ~ sex + age + year, data = pbc2,
random = ~ year | id, family = binomial())
fm3 <- mixed_model(ascites ~ year + age, data = pbc2,
random = ~ year | id, family = binomial())
# [2] Save all the fitted mixed-effects models in a list.
Mixed <- list(fm1, fm2, fm3)
# [3] Fit a Cox model, specifying the baseline covariates to be included in the
# joint model.
fCox1 <- coxph(Surv(years, status2) ~ drug + age, data = pbc2.id)
# [4] Specify the list of formulas to be passed to the functional_forms argument
# of jm().
fForms <- list("log(serBilir)" = ~ value(log(serBilir)) + slope(log(serBilir)),
"hepatomegaly" = ~ area(hepatomegaly),
"ascites" = ~ value(ascites) + area(ascites))
# [5] The joint model is fitted using a call to jm() and passing the list
# to the functional_forms argument.
joint_model_fit_2 <- jm(fCox1, Mixed, time_var = "year",
functional_forms = fForms, n_chains = 1L,
n_iter = 11000L, n_burnin = 1000L)
summary(joint_model_fit_2)
#>
#> Call:
#> JMbayes2::jm(Surv_object = fCox1, Mixed_objects = Mixed, time_var = "year",
#> functional_forms = fForms, n_chains = 1L, n_iter = 11000L,
#> n_burnin = 1000L)
#>
#> Data Descriptives:
#> Number of Groups: 312 Number of events: 140 (44.9%)
#> Number of Observations:
#> log(serBilir): 1945
#> hepatomegaly: 1884
#> ascites: 1885
#>
#> DIC WAIC LPML
#> marginal 6643.644 6952.261 -4059.774
#> conditional 8992.791 8720.794 -4830.170
#>
#> Random-effects covariance matrix:
#>
#> StdDev Corr
#> (Intr) 0.9883 (Intr) year (Intr) year (Intr)
#> year 0.1813 0.4185
#> (Intr) 3.3719 0.5278 0.3471
#> year 0.5866 0.0491 0.3639 -0.3638
#> (Intr) 2.2434 0.6558 0.5818 0.6176 -0.1046
#> year 0.3799 0.4802 0.6989 0.4232 0.3547 0.3394
#>
#> Survival Outcome:
#> Mean StDev 2.5% 97.5% P
#> drugD-penicil -0.1146 0.2661 -0.6416 0.3927 0.6798
#> age 0.0484 0.0137 0.0208 0.0754 0.0000
#> value(log(serBilir)) 0.9236 0.2028 0.5630 1.3718 0.0000
#> slope(log(serBilir)) 3.8810 1.3348 1.4004 6.6187 0.0026
#> area(hepatomegaly) 0.1137 0.0836 -0.0660 0.2775 0.1734
#> value(ascites) -0.6728 0.2285 -1.0753 -0.1067 0.0034
#> area(ascites) 1.0142 0.2915 0.1782 1.4328 0.0028
#>
#> Longitudinal Outcome: log(serBilir) (family = gaussian, link = identity)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) 0.7067 0.1429 0.4254 0.9870 0.0000
#> year 0.2605 0.0300 0.2020 0.3203 0.0000
#> sexfemale -0.2451 0.1481 -0.5341 0.0420 0.0988
#> year:sexfemale -0.0716 0.0305 -0.1324 -0.0125 0.0180
#> sigma 0.3483 0.0066 0.3357 0.3618 0.0000
#>
#> Longitudinal Outcome: hepatomegaly (family = binomial, link = logit)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) 0.2790 1.0209 -1.7124 2.2872 0.7926
#> sexfemale -0.9275 0.5312 -1.9833 0.0903 0.0756
#> age 0.0138 0.0165 -0.0190 0.0458 0.3974
#> year 0.2594 0.0730 0.1222 0.4067 0.0004
#>
#> Longitudinal Outcome: ascites (family = binomial, link = logit)
#> Mean StDev 2.5% 97.5% P
#> (Intercept) -8.0466 0.8839 -9.8390 -6.3740 0
#> year 0.4513 0.0598 0.3147 0.5598 0
#> age 0.0733 0.0153 0.0443 0.1052 0
#>
#> MCMC summary:
#> chains: 1
#> iterations per chain: 11000
#> burn-in per chain: 1000
#> thinning: 1
#> time: 1.5 min
# }