Competing Risks
Dimitris Rizopoulos
2026-02-02
Source:vignettes/Competing_Risks.Rmd
Competing_Risks.RmdJoint Models with Competing Risks
Prepare data
The first step in fitting a joint model for competing events in
JMbayes2 is to prepare the data for the event process.
If there are K competing events, each
subject must have K rows, one for each
possible cause. The observed event time T_i of each subject is repeated K times, and there are two indicator
variables, namely one identifying the cause and one indicating whether
the corresponding event type is the one that occurred. Standard survival
datasets that include a single row per patient can be easily transformed
to the competing risks long format using the function
crisk_setup(). This function accepts as main arguments the
survival data in the standard format with a single row per patient, the
name of the status variable, and the level in this status variable that
corresponds to censoring. We illustrate the use of this function in the
PBC data, where we treat as competing risks transplantation and
death:
pbc2.id[pbc2.id$id %in% c(1, 2, 5), c("id", "years", "status")]
#> id years status
#> 1 1 1.095170 dead
#> 2 2 14.152338 alive
#> 5 5 4.120578 transplanted
pbc2.idCR <- crisk_setup(pbc2.id, statusVar = "status", censLevel = "alive",
nameStrata = "CR")
pbc2.idCR[pbc2.idCR$id %in% c(1, 2, 5),
c("id", "years", "status", "status2", "CR")]
#> id years status status2 CR
#> 1 1 1.095170 dead 1 dead
#> 1.1 1 1.095170 dead 0 transplanted
#> 2 2 14.152338 alive 0 dead
#> 2.1 2 14.152338 alive 0 transplanted
#> 5 5 4.120578 transplanted 0 dead
#> 5.1 5 4.120578 transplanted 1 transplantedNote that each patient is now represented by two rows (we have two
possible causes of discontinuation from the study, death, and
transplantation), the event time variable years is
identical in both rows of each patient, variable CR denotes
the cause for the specific line of the long dataset, and variable
status2 equals 1 if the corresponding event occurred.
Fit models
For the event process, we specify cause-specific relative risk
models. Using dataset pbc2.idCR, we fit the corresponding
cause-specific Cox regressions by including the interaction terms of age
and treatment with variable CR, which is treated as a
stratification variable using the strata() function:
CoxFit_CR <- coxph(Surv(years, status2) ~ (age + drug):strata(CR),
data = pbc2.idCR)We include two longitudinal outcomes for the longitudinal process: serum bilirubin and the prothrombin time. For the former, we use quadratic orthogonal polynomials in the fixed- and random-effects parts, and for the latter, linear evolutions:
fm1 <- lme(log(serBilir) ~ poly(year, 2) * drug, data = pbc2,
random = ~ poly(year, 2) | id)
fm2 <- lme(prothrombin ~ year * drug, data = pbc2, random = ~ year | id)To specify that each longitudinal outcome has a separate association coefficient per competing risk, we define the corresponding functional forms:
CR_forms <- list(
"log(serBilir)" = ~ value(log(serBilir)):CR,
"prothrombin" = ~ value(prothrombin):CR
)Finally, the competing risks joint model is fitted with the following
call to jm() (due to the complexity of the model, we have
increased the number of MCMC iterations and the burn-in period per
chain). Also, because relatively few patients received a
transplantation, we specify a Weibull baseline hazard function for this
competing event, and the default penalized B-spline approximation for
death:
jFit_CR <- jm(CoxFit_CR, list(fm1, fm2), time_var = "year",
functional_forms = CR_forms,
base_hazard = c("weibull", NA),
n_iter = 25000L, n_burnin = 5000L, n_thin = 5L)
summary(jFit_CR)
#>
#> Call:
#> JMbayes2::jm(Surv_object = CoxFit_CR, Mixed_objects = list(fm1,
#> fm2), time_var = "year", functional_forms = CR_forms, base_hazard = c("weibull",
#> NA), n_iter = 25000L, n_burnin = 5000L, n_thin = 5L)
#>
#> Data Descriptives:
#> Number of Groups: 312 Number of events: 169 (27.1%)
#> Number of Observations:
#> log(serBilir): 1945
#> prothrombin: 1945
#>
#> DIC WAIC LPML
#> marginal 10826.05 11552.64 -6915.799
#> conditional 15753.47 15441.05 -8229.663
#>
#> Random-effects covariance matrix:
#>
#> StdDev Corr
#> (Intr) 1.3413 (Intr) p(,2)1 p(,2)2 (Intr)
#> p(,2)1 23.0242 0.7078
#> p(,2)2 12.3462 -0.2624 -0.1501
#> (Intr) 0.7850 0.6336 0.4416 -0.3343
#> year 0.3251 0.4292 0.3369 -0.0495 0.0398
#>
#> Survival Outcome:
#> Mean StDev 2.5% 97.5% P
#> age:strata(CR)transplanted -0.0786 0.0253 -0.1301 -0.0315 0.0007
#> age:strata(CR)dead 0.0656 0.0099 0.0468 0.0857 0.0000
#> drugD-penicil:strata(CR)transplanted -0.3134 0.3902 -1.1019 0.4500 0.4107
#> drugD-penicil:strata(CR)dead 0.0073 0.1883 -0.3626 0.3763 0.9802
#> value(log(serBilir)):CRtransplanted 1.0878 0.2153 0.6830 1.5252 0.0000
#> value(log(serBilir)):CRdead 1.4680 0.1194 1.2463 1.7156 0.0000
#> value(prothrombin):CRtransplanted -0.1225 0.1649 -0.4453 0.2001 0.4632
#> value(prothrombin):CRdead 0.1527 0.0463 0.0562 0.2392 0.0050
#> Rhat
#> age:strata(CR)transplanted 1.0301
#> age:strata(CR)dead 1.0068
#> drugD-penicil:strata(CR)transplanted 1.0102
#> drugD-penicil:strata(CR)dead 1.0032
#> value(log(serBilir)):CRtransplanted 1.0054
#> value(log(serBilir)):CRdead 1.0186
#> value(prothrombin):CRtransplanted 1.0732
#> value(prothrombin):CRdead 1.0176
#>
#> Longitudinal Outcome: log(serBilir) (family = gaussian, link = identity)
#> Mean StDev 2.5% 97.5% P Rhat
#> (Intercept) 1.2023 0.1139 0.9797 1.4258 0.0000 1.0035
#> poly(year, 2)1 28.0606 3.0382 22.3560 34.2529 0.0000 1.0125
#> poly(year, 2)2 1.2012 1.7767 -2.2584 4.7177 0.4997 1.0075
#> drugD-penicil -0.1957 0.1576 -0.5046 0.1079 0.2195 1.0002
#> p(,2)1 -3.4221 3.6144 -10.6940 3.5380 0.3425 1.0004
#> p(,2)2 -1.1121 2.1833 -5.4202 3.1215 0.6052 1.0012
#> sigma 0.3025 0.0062 0.2906 0.3151 0.0000 0.9999
#>
#> Longitudinal Outcome: prothrombin (family = gaussian, link = identity)
#> Mean StDev 2.5% 97.5% P Rhat
#> (Intercept) 10.6399 0.0838 10.4751 10.8046 0.0000 1.0016
#> year 0.2895 0.0394 0.2132 0.3689 0.0000 1.0098
#> drugD-penicil -0.1000 0.1174 -0.3279 0.1304 0.3962 1.0003
#> year:drugD-penicil -0.0205 0.0518 -0.1236 0.0799 0.6977 1.0003
#> sigma 1.0550 0.0204 1.0157 1.0957 0.0000 1.0014
#>
#> MCMC summary:
#> chains: 3
#> iterations per chain: 25000
#> burn-in per chain: 5000
#> thinning: 5
#> time: 5.2 minDynamic predictions
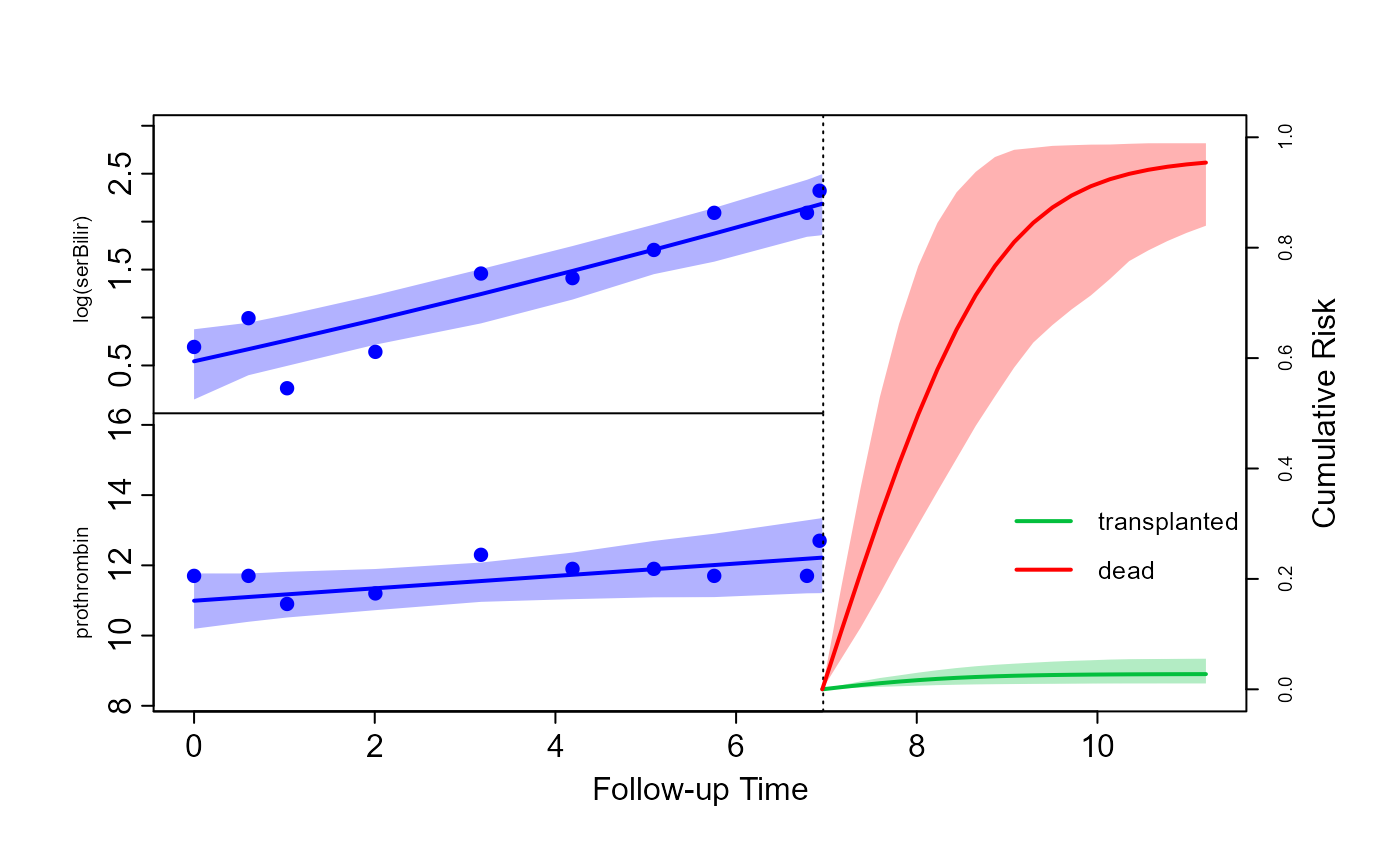
Based on the fitted competing risks joint model, we will illustrate how (dynamic) predictions can be calculated for the cause-specific cumulative risk probabilities. As an example, we will show these calculations for Patient 81 from the PBC dataset. First, we extract the data on this subject.
ND_long <- pbc2[pbc2$id == 81, ]
ND_event <- pbc2.idCR[pbc2.idCR$id == 81, ]
ND_event$status2 <- 0
ND <- list(newdataL = ND_long, newdataE = ND_event)The first line extracts the longitudinal measurements, and the second
line extracts the event times per cause (i.e., death and
transplantation). This patient died at 6.95 years, but to make the
calculation of cause-specific cumulative risk more relevant, we presume
that she did not have the event, and we set the event status variable
status2 to zero. The last line combines the two datasets in
a list. Note: this last step is a prerequisite from the
predict() method for competing risks joint model. That is,
the datasets provided in the arguments newdata and
newdata2 need to be named lists with two components. The
first component needs to be named newdataL and contain the
dataset with the longitudinal measurements. The second component needs
to be named newdataE and contain the dataset with the event
information.
The predictions are calculated using the predict()
method. The first call to this function calculates the prediction for
the longitudinal outcomes at the times provided in the
times argument, and the second call calculates the
cause-specific cumulative risk probabilities. By setting the argument
return_newdata to TRUE in both calls, we can
use the corresponding plot() method to depict the
predictions:
predLong <- predict(jFit_CR, newdata = ND, return_newdata = TRUE,
times = seq(6.5, 15, length = 25))
predEvent <- predict(jFit_CR, newdata = ND, return_newdata = TRUE,
process = "event")
plot(predLong, predEvent, outcomes = 1:2, ylim_long_outcome_range = FALSE,
col_line_event = c("#03BF3D", "#FF0000"),
fill_CI_event = c("#03BF3D4D", "#FF00004D"), pos_ylab_long = c(1.5, 11.5))
legend(x = 8.1, y = 0.45, legend = levels(pbc2.idCR$CR),
lty = 1, lwd = 2, col = c("#03BF3D", "#FF0000"), bty = "n", cex = 0.8)